Buys a Domain
https://domains.google.com/registrar/search

Hosting a static website
This tutorial describes how to configure a Cloud Storage bucket to host a static website for a domain you own. Static web pages can contain client-side technologies such as HTML, CSS, and JavaScript. They cannot contain dynamic content such as server-side scripts like PHP.
Point your domain to Cloud Storage by using a CNAME record.
Create a bucket that is linked to your domain.
Upload and share your site's files.
Test the website.
Have a domain that you own or manage. If you don't have an existing domain, there are many services through which you can register a new domain
Make sure you are verifying the top-level domain, such as example.com, and not a subdomain, such as www.example.com.
tutorial works best if you have at least an index page (index.html) and a 404 page (404.html).
Since Cloud Storage doesn't support custom domains with HTTPS on its own, this tutorial uses Cloud Storage with HTTP(S) Load Balancing to serve content from a custom domain over HTTPS. For more ways to serve content from a custom domain over HTTPS, see the related troubleshooting topic. You can also use Cloud Storage to serve custom domain content over HTTP, which doesn't require a load balancer.
For examples and tips on static web pages, including how to host static assets for a dynamic website, see the Static Website page.
Objectives
This tutorial shows you how to:
Create a bucket.
Upload and share your site's files.
Set up a load balancer and SSL certificate.
Connect your load balancer to your bucket.
Point your domain to your load balancer using an A record.
Test the website.
Specialty pages
Index pages
An index page (also called a webserver directory index) is a file served to visitors when they request a URL that doesn't have an associated file. When you assign a MainPageSuffix property, Cloud Storage looks for a file with that name whose prefix matches the URL the visitor requested.
For example, say you set the MainPageSuffix of your static website to index.html. Additionally, say you have no file named directory in your bucket www.example.com. In this situation, if a user requests the URL http://www.example.com/directory, Cloud Storage attempts to serve the file www.example.com/directory/index.html. If that file also doesn't exist, Cloud Storage returns an error page.
The MainPageSuffix also controls the file served when users request the top level site. Continuing the above example, if a user requests http://www.example.com, Cloud Storage attempts to serve the file www.example.com/index.html.
When attempting to access a URL with a trailing slash, such as http://www.example.com/dir/, see Troubleshooting.
Error page
The error page is the file returned to visitors of your static site who request a URL that does not correspond to an existing file. If you have assigned a MainPageSuffix, Cloud Storage only returns the error page if there is neither a file with the requested name nor an applicable index page.
When returning an error page, the http response code is 404. The property that controls which file acts as the error page is NotFoundPage. If you don't set NotFoundPage, users receive a generic error page.
Website configuration examples
Three-object bucket
Suppose a bucket named www.example.com has been configured as a website with the following settings and files:
MainPageSuffix = "index.html"
NotFoundPage = "404.html"
The bucket contains three publicly shared objects: "index.html", "404.html", and "dir/index.html".
https://download.huihoo.com/google/gdgdevkit/DVD1/developers.google.com/storage/docs/website-configuration.html
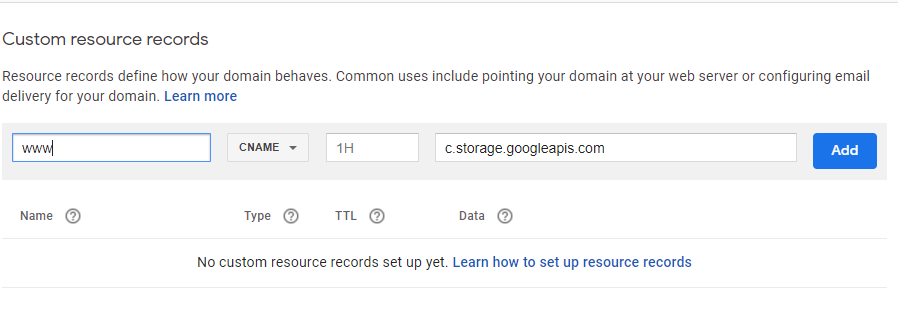
Creating a CNAME record
A CNAME record is a type of DNS record. It directs traffic that requests a URL from your domain to the resources you want to serve, in this case objects in your Cloud Storage buckets. For www.example.com, the CNAME record might contain the following information:
NAME TYPE DATA
www.example.com CNAME c.storage.googleapis.com
To connect your domain to Cloud Storage:
Create a CNAME record that points to c.storage.googleapis.com.
DNS does not support creating a CNAME record on a root domain, such as example.com, so in most cases, you must create your CNAME record on a subdomain, such as www.example.com or myblog.example.com
Creating a bucket
Create a bucket whose name matches the CNAME you created for your domain.
For example, if you added a CNAME record pointing www.example.com to c.storage.googleapis.com., then create a bucket with the name "www.example.com".
Open the Cloud Storage browser in the Google Cloud Console.
Click Create bucket to open the bucket creation form.
Enter your bucket information and click Continue to complete each step:
The Name of your bucket.
The Storage class and Location for your bucket.
The Access control model for your bucket.
Click Create.
If successful, you are taken to the bucket's page with the text "There are no live objects in this bucket."
DNS

Creating a CNAME record
A CNAME record is a type of DNS record. It directs traffic that requests a URL from your domain to the resources you want to serve, in this case objects in your Cloud Storage buckets. For www.example.com, the CNAME record might contain the following information:
NAME TYPE DATA
www.example.com CNAME c.storage.googleapis.com.
Index pages
An index page (also called a webserver directory index) is a file served to visitors when they request a URL that doesn't have an associated file. When you assign a MainPageSuffix, Cloud Storage looks for a file with that name whose prefix matches the URL the visitor requested.
For example, say you set the MainPageSuffix of your static website to index.html. Additionally, say you have no file named directory in your bucket www.example.com. In this situation, if a user requests the URL http://www.example.com/directory, Cloud Storage attempts to serve the file www.example.com/directory/index.html. If that file also doesn't exist, Cloud Storage returns an error page.
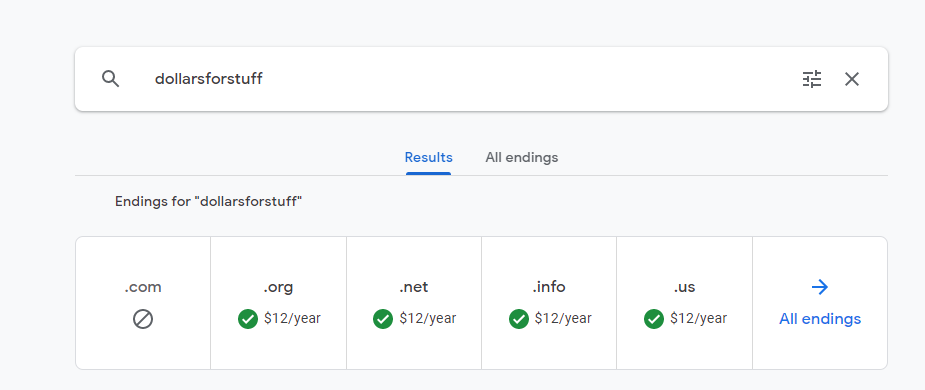
Search for a domain name
Se
For $12 a year you can own it
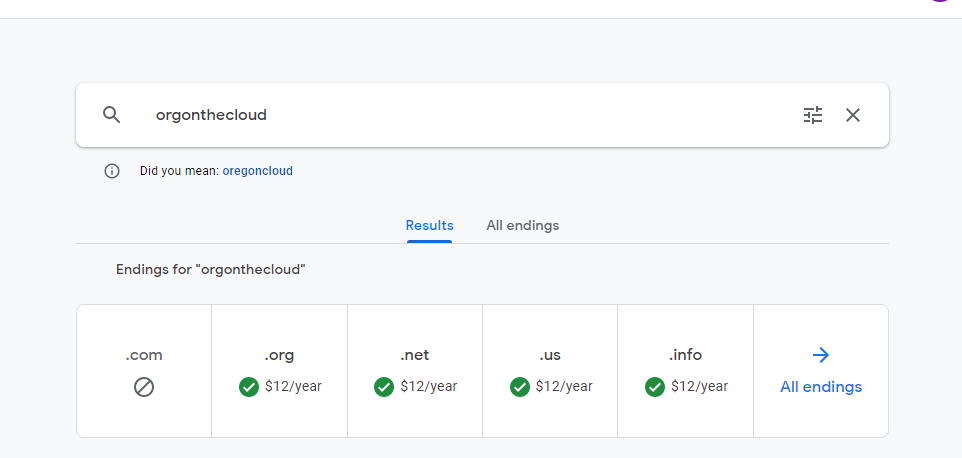
Create a Cloud Storage Bucket with the www.orgonthecloud.com
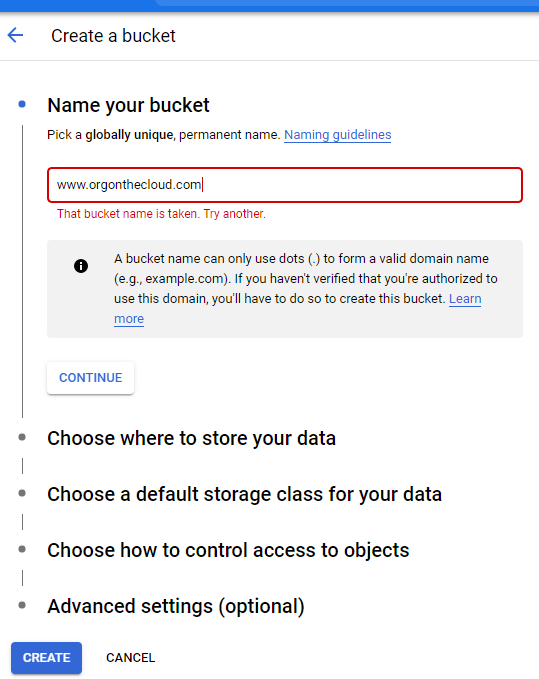
Make it public

Access the DNS

configure your DNS records to provide a CNAME alias to c.storage.googleapis.com
The CNAME record connect your domain to www.orgonthecloud.com

gsutil web set -m index.html -e 404.html gs://www.orgonthecloud.com
Upload your index.html and 404.html files
gsutil web set -m index.html -e 404.html gs://www.orgonthecloud.com
Setting website configuration on gs://www.orgonthecloud.com/...
john_iacovacci1@cloudshell:~/orgonthecloud (uconn-engr)$
MY INDEX PAGE WILL APPEAR WHEN I GOT TO www.orgonthecloud.com
What is SEO?
SEO stands for “search engine optimization.” In simple terms, it means the process of improving your site to increase its visibility for relevant searches. The better visibility your pages have in search results, the more likely you are to garner attention and attract prospective and existing customers to your business.
How does SEO work?
Search engines such as Google and Bing use bots to crawl pages on the web, going from site to site, collecting information about those pages and putting them in an index. Next, algorithms analyze pages in the index, taking into account hundreds of ranking factors or signals, to determine the order pages should appear in the search results for a given query.
The search algorithms are designed to surface relevant, authoritative pages and provide users with an efficient search experience. Optimizing your site and content with these factors in mind can help your pages rank higher in the search results.
Algorithms turn information to search results
Higher ranking means better results
Crawls web and absorb all content
Words matter - need to be relevant to what the search is
Titles matter - the HTML <title> should summarize the page
Links matter - links to your web pages is good
Words in Links
Reputation
The following factors are assumed to be closely connected to rankings:
number of backlinks
sitemap and internal linking
usage of keywords in text elements like meta titles, meta descriptions, text etc.
term optimization of content, based on comparison with other documents on the same topic (proof and relevant terms, topic/content clusters, WDF*IDF)
URL structure
trust assigned to the page
page load time (site speed)
time on site and bounce rate (here: how long a visitor spends on the page before they return to the SERP)
CTR in the SERPs, i.e. how often searchers click on the result
and presumably many other factors like page traffic, authorship, how up-to-date a page is
CrawlingImagine that you need to explore an unknown country. You start in a small town and drive down a road that connects you to the next town. You take the next road to the next town, and the next road after that. If you drive down every possible road from your starting point, you’ll eventually end up discovering every town.
This is how Google works–except the towns are web pages, and the roads connecting them are backlinks.
Etc.
Indexing
After finding pages on the web, the spiders then extract data from them and store, or “index,” said data in Google’s database—to then be shown in search results.
Using this beginner's guide, we can follow these seven steps to successful SEO:
Crawl accessibility so engines can read your website
Compelling content that answers the searcher’s query
Keyword optimized to attract searchers & engines
Great user experience including a fast load speed and compelling UX
Share-worthy content that earns links, citations, and amplification
Title, URL, & description to draw high CTR in the rankings
Snippet/schema markup to stand out in SERPs
increasing both the quality and quantity of website traffic
understanding what people allow you to connect to the people who are
searching online for the solutions you offer.re searching for online
discovering and cataloguing all available content on the Internet
process known as “crawling and indexing,” and then ordering it by how well it matches the query in a process we refer to as “ranking.”
organic search results are the ones that are earned through effective SEO
search engine results pages — often referred to as “SERPs”
Google Webmaster Guidelines
Basic principles:
Make pages primarily for users, not search engines.
Don't deceive your users.
Avoid tricks intended to improve search engine rankings. A good rule of thumb is whether you'd feel comfortable explaining what you've done to a website to a Google employee. Another useful test is to ask, "Does this help my users? Would I do this if search engines didn't exist?"
Think about what makes your website unique, valuable, or engaging.
Things to avoid:
Automatically generated content
Participating in link schemes
Creating pages with little or no original content (i.e. copied from somewhere else)
Cloaking — the practice of showing search engine crawlers different content than visitors.
Hidden text and links
Doorway pages — pages created to rank well for specific searches to funnel traffic to your website.
Search engines have three primary functions:
Crawl: Scour the Internet for content, looking over the code/content for each URL they find.
Index: Store and organize the content found during the crawling process. Once a page is in the index, it’s in the running to be displayed as a result to relevant queries.
Rank: Provide the pieces of content that will best answer a searcher's query, which means that results are ordered by most relevant to least relevant.
If you're not showing up anywhere in the search results, there are a few possible reasons why:
Your site is brand new and hasn't been crawled yet.
Your site isn't linked to from any external websites.
Your site's navigation makes it hard for a robot to crawl it effectively.
Your site contains some basic code called crawler directives that is blocking search engines.
Your site has been penalized by Google for spammy tactics.
Robots.txt
Robots.txt files are located in the root directory of websites (ex. yourdomain.com/robots.txt) and suggest which parts of your site search engines should and shouldn't crawl, as well as the speed at which they crawl your site, via specific robots.txt directives.
How Googlebot treats robots.txt files
If Googlebot can't find a robots.txt file for a site, it proceeds to crawl the site.
If Googlebot finds a robots.txt file for a site, it will usually abide by the suggestions and proceed to crawl the site.
If Googlebot encounters an error while trying to access a site’s robots.txt file and can't determine if one exists or not, it won't crawl the site.
Keyword research provides you with specific search data that can help you answer questions like:
What are people searching for?
How many people are searching for it?
In what format do they want that information?
Before keyword research, ask questions
Before you can help a business grow through search engine optimization, you first have to understand who they are, who their customers are, and their goals.
This is where corners are often cut. Too many people bypass this crucial planning step because keyword research takes time, and why spend the time when you already know what you want to rank for?
The answer is that what you want to rank for and what your audience actually wants are often two wildly different things. Focusing on your audience and then using keyword data to hone those insights will make for much more successful campaigns than focusing on arbitrary keywords.
What terms are people searching for?
You may have a way of describing what you do, but how does your audience search for the product, service, or information you provide? Answering this question is a crucial first step in the keyword research process.
Discovering keywords
You likely have a few keywords in mind that you would like to rank for. These will be things like your products, services, or other topics your website addresses, and they are great seed keywords for your research, so start there!
https://moz.com/beginners-guide-to-seo/keyword-research
No comments:
Post a Comment