Chapter 19. BigQuery: highly scalable data warehouse
What is BigQuery?
How does BigQuery work under the hood?
Bulk loading and streaming data into BigQuery
Querying data
How pricing works
Waiting for a query to finish running.
MapReduce (for example, Hadoop) to speed up some of the larger jobs and then been frustrated again when every little change meant you had to change your code, recompile, redeploy, and run the job again.
Hadoop MapReduce is a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner.
A MapReduce job usually splits the input data-set into independent chunks which are processed by the map tasks in a completely parallel manner. The framework sorts the outputs of the maps, which are then input to the reduce tasks. Typically both the input and the output of the job are stored in a file-system. The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks.
19.1. What is BigQuery?
BigQuery is a relational-style cloud database that’s capable of querying enormous amounts of data in seconds rather than hours.
BigQuery uses SQL instead of Java or C++ code.
BigQuery is capable of running traditional OLTP-style queries (for example, UPDATE table SET name = 'Jimmy' where id = 1).
In Online transaction processing (OLTP), information systems typically facilitate and manage transaction-oriented applications.
Use it as an analytical tool for scanning, filtering, and aggregating data.
19.1.1. Why BigQuery?
Why you might use BigQuery instead of some of the other systems out there
MySQL will become overloaded, and performance will degrade.
Tune MySQL’s performance-related parameters so that certain queries run faster.
Turn on read-replicas so you aren’t running super-difficult queries on the same database that handles user-facing requests.
Look at using a data warehouse system like Netezza, but the price for those systems can be high.
BigQuery provides some of the power of traditional data warehouse systems while only charging for what you use.
19.1.2. How does BigQuery work?
Coolest thing about BigQuery is generally thought to be the sheer amount of data it can handle.
Problem’s two parts.
Filter billions of rows of data, you need to do billions of comparisons, which require a lot of computing power.
Second, you need to do the comparisons on data that’s stored somewhere, and the drives that store that data have limits on how quickly it can flow out of them to the computer that’s doing those comparisons..
Scaling computing capacity
People originally tackled the computation aspect of this problem by using the MapReduce algorithm.
Data is chopped into manageable pieces (the map stage) and then reduced to a summary of the pieces (the reduce stage).
Speeds up the entire process by parallelizing the work to lots and lots of different computers.
MapReduce, you could speed this up by using 1,000 computers, with each one responsible for counting one one-thousandth of the rows, and then summing up the 1,000 separate counts to get the full count (figure 19.1).

This is what BigQuery does under the hood.
Google Cloud Platform has thousands of CPUs in a pool dedicated to handling requests from BigQuery.
Execute a query, it momentarily gives you access to that computing capacity.
BigQuery joins them all back together and gives you a query result.
Scaling storage throughput
Solved the computational capacity problem by splitting the problem up into many chunks and using lots of CPUs to crunch on each piece in parallel.
The single disk acts as a bottleneck because it has a limited data transfer rate.
Split the database across lots of different physical drives (called sharding) (figure 19.2) so that when all of the CPUs started asking for their chunks of data, lots of different drives would handle transferring them.
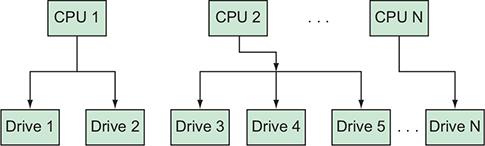
Sharding the data across lots of drives and transporting it to lots of CPUs for processing allows you to potentially read and process enormous amounts of data incredibly quickly.
Google is doing this, using a custom-built storage system called Colossus, which handles splitting and replicating all of the data so that BigQuery doesn’t have to worry about it.
19.1.3. Concepts
BigQuery is incredibly SQL-like, so I can draw close comparisons with the things you’re already familiar with in systems like MySQL.
Datasets and tables
Like a relational database has databases that contain tables, BigQuery has datasets that contain tables (figure 19.3). The datasets mainly act as containers, and the tables, again like a relational database, are collections of rows.

Each table contained in the dataset is defined by a set schema, so you can think of BigQuery in a traditional grid, where each row has cells that fit the types and limits of the columns defined in the schema.
Unlike in a traditional relational database, BigQuery rows typically don’t have a unique identifier column, primarily because BigQuery isn’t meant for transactional queries where a unique ID is required to address a single row.
Constraints like uniqueness in even a single column aren’t available.
It’s not possible to guarantee that if you request to update data in BigQuery, it will only address the exact row you intended.
Otherwise, BigQuery will accept most common SQL-style requests, like SELECT statements; UPDATE, INSERT, and DELETE statements with potentially complex WHERE clauses; and fancy JOIN operations.
You can transfer the querying power from BigQuery over to other storage services.
BigQuery can run queries over data stored in other storage services in Google Cloud Platform, such as Cloud Storage, Cloud Datastore, or Cloud Bigtable.
Schemas
BigQuery tables have a structured schema, which in turn has the standard data types you’re used to, such as INTEGER, TIMESTAMP, and STRING (sometimes known as VARCHAR).
Fields can be required or nullable (like NULL or NOT NULL).
Unlike with a relational database, you define and set schemas as part of an API call rather than running them as a query.
BigQuery doesn’t use SQL for requests related to the schema. Instead, you send those types of queries to the BigQuery API itself, and the schema is part of that API call.
People with fields for each person’s name, age, and birth date.
Make an API call to the BigQuery service, passing along the schema as part of that message. You can represent the schema itself as a list of JSON objects, each with information about a single field. In the following example listing, notice how the NULLABLE and REQUIRED (SQL’s NOT NULL) are listed as the mode of the field.
[
{"name": "name", "type": "STRING", "mode": "REQUIRED"},
{"name": "age", "type": "INTEGER", "mode": "NULLABLE"},
{"name": "birthdate", "type": "TIMESTAMP", "mode": "NULLABLE"}
]
Mode called REPEATED.
Repeated fields do as their name implies, taking the type provided and turning it into an array equivalent.
A repeated INTEGER field acts like an array of integers.
Field type called RECORD acts like a JSON object, allowing you to nest rows within rows.
The people table could have a RECORD type field called favorite_book.
Would have fields for the title and author (which would both be STRING types).
BigQuery, this type of inlining or denormalizing is supported and can be useful, particularly if the data (in this case, the book title and author) is never needed in a different context.
BigQuery has two nonstandard field modifiers (the REPEATED mode and the RECORD type) and lacks some of the normalization features of traditional SQL databases (such as UNIQUE, FOREIGN KEY, and explicit indexes).
Jobs
BigQuery uses jobs to represent work that will likely take a while to complete.
Create a semi persistent resource called a job that’s responsible for executing the work requested.
Returning the success or failure result when the work is done or is halted.
Querying for data
Loading new data into BigQuery
Copying data from one table to another
Extracting (or exporting) data from BigQuery to somewhere else (like Google Cloud Storage [GCS])
Taking data from one place and putting it in another, potentially with some transformation applied over the data somewhere along the way.
Copy job is sort of like a special type of query job, where the query (in SQL here) is equivalent to SELECT * FROM table.
Jobs are treated as unique resources, you can perform the typical operations over jobs that you can over things like tables or datasets.
19.2. Interacting with BigQuery
Accessible via its API, so you have several convenient ways of talking to it: with the UI in the Cloud Console, on the command line with the bq tool.
19.2.1. Querying data
Cloud Console and choosing BigQuery from the left-side navigation menu.
Click Public Datasets, you’ll land on a page showing off a bunch of these datasets.
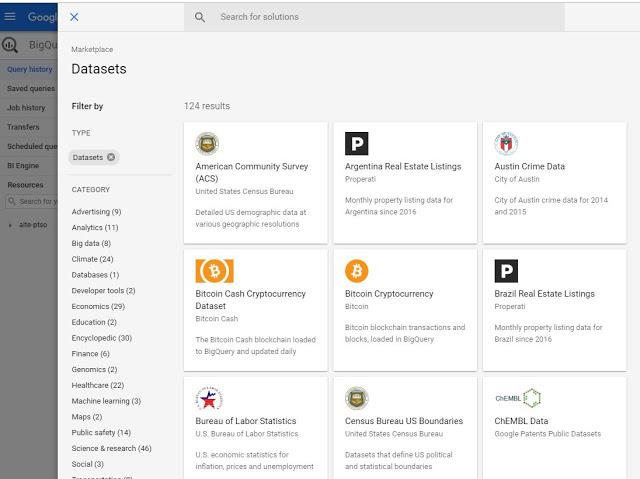
Try out the yellow taxi dataset.

See the list of fields available, their data types, and a short description of the data that lives in each field.
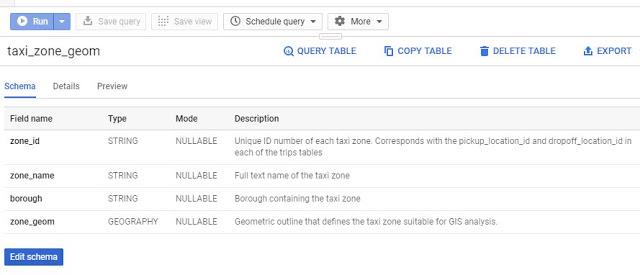
Click the Details tab at the top, you’ll be able to see an overview of the table.

Starting with a query that any other database could probably handle easily as long as there was an index.
SELECT total_amount, pickup_datetime, trip_distance
FROM `nyc-tlc.yellow.trips`
ORDER BY total_amount DESC
LIMIT 1;
Query asks the table for some details sorted by the total trip cost but only gives you the first (most expensive) trip. B
Need to tell BigQuery not to use the legacy (old) SQL-style syntax.
Newer syntax uses back ticks for escaping table names rather than the square brackets from when BigQuery first launched.
BigQuery will get to work and should return a result in around two seconds.
Show you how much data it queried in that time, which in my case was about 25 GB.
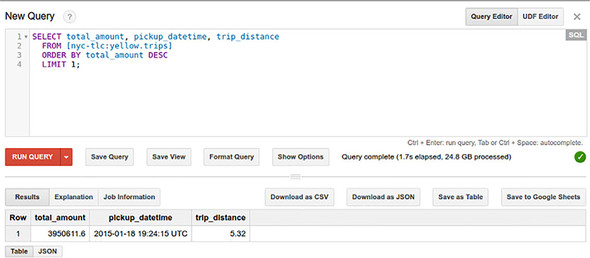
Figure out what was the most common hour of the day that people were picked up?
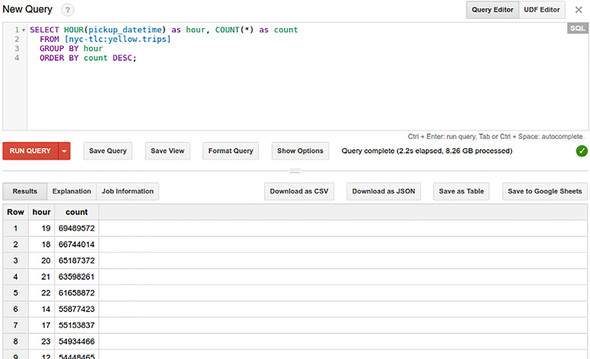
SELECT HOUR(pickup_datetime) as hour, COUNT(*) as count
FROM `nyc-tlc.yellow.trips`
GROUP BY hour
ORDER BY count DESC;
Query shows that the evening pickups are most common (6–10 p.m.) and the early morning pickups are least common .
SELECT DAYOFWEEK(pickup_datetime) as day, HOUR(pickup_datetime) as hour,
COUNT(*) as count
FROM `nyc-tlc.yellow.trips`
GROUP BY day, hour
ORDER BY count DESC;

MySQL can do all of this.” If so, BigQuery has done its job. The whole purpose of BigQuery is to feel like running an analytical query with any other SQL database, but way faster.
This is where the client library (@google-cloud/bigquery) comes in. To see how it works with BigQuery, you can write some code that finds the most expensive ride, as in the following listing.
const BigQuery = require('@google-cloud/bigquery');
const bigquery = new BigQuery({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
const query = `SELECT total_amount, pickup_datetime, trip_distance
FROM \`nyc-tlc.yellow.trips\`
ORDER BY total_amount DESC
LIMIT 1;`
bigquery.createQueryJob(query).then((data) => {
const job = data[0];
return job.getQueryResults({timeoutMs: 10000});
}).then((data) => {
const rows = data[0];
console.log(rows[0]);
});
{ total_amount: 3950611.6,
pickup_datetime: { value: '2015-01-18 19:24:15.000' },
trip_distance: 5.32 }
find the total cost of all of the trips? Try this:
SELECT SUM(total_amount) FROM `nyc-tlc.yellow.trips`;
BigQuery’s API will apply some automatically generated field names to the unnamed fields, using the order of the field in the query as an index:
{ f0_: 14569463158.355078 }
19.2.2. Loading data
BigQuery jobs support multiple types of operations, one of them being for loading new data.
BigQuery tables themselves may be based on other data sources, such as Bigtable, Cloud Datastore, or Cloud Storage.
Bulk loading data into BigQuery
Big chunk of arbitrary data (such as a bunch of CSVs or JSON objects) and loading it into a BigQuery table.
Note:
JSON Objects
Object Syntax
Example
{ "name":"John", "age":30, "car":null }
JSON objects are surrounded by curly braces {}.
JSON objects are written in key/value pairs.
Keys must be strings, and values must be a valid JSON data type
(string, number, object, array, boolean or null).
Keys and values are separated by a colon.
Each key/value pair is separated by a comma.
CSV - comma-separated values file is a delimited text file that uses a comma to separate values. Each line of the file is a data record. Each record consists of one or more fields, separated by commas. The use of the comma as a field separator is the source of the name for this file format.
Recreating a table to store the data from taxi rides, similar to the one you’ve been querying in the shared dataset.
Create a dataset, then a table, and then you need to set the schema to fit your data.
BigQuery UI in the Cloud Console, so start by heading back to BigQuery’s interface. On the left-hand side, you should see a “No datasets found” message, so use the little arrow next to your project name and choose Create New Dataset .
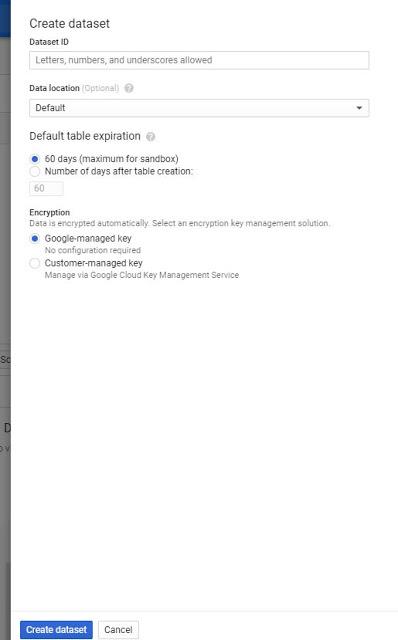
Choose the ID for your dataset.
No hyphens. Because BigQuery dataset (and table) IDs are used in SQL queries, hyphens are prohibited. As a result, it’s common to use underscores where you’d usually use hyphens (test_dataset_id .
Click OK, and your dataset should appear right away, so it’s time to create your new table.
That tables are mutable, so if you forget a field, it’s not the end of the world
If you add a field after you’ve already loaded data, the rows that you have will get a NULL value for the new field.
1493033027,1493033627,8.42
1493033004,1493033943,18.61
1493033102,1493033609,9.17
1493032027,1493033801,24.97
You can define a table called trips, with those three fields under the Schema section. Lastly, if you put the CSV data from those four data points into a file, you can use.
Checked the File Upload data source .
[
{
"mode": "REQUIRED",
"name": "pickup_time",
"type": "TIMESTAMP"
},
{
"mode": "REQUIRED",
"name": "dropoff_time",
"type": "TIMESTAMP"
},
{
"mode": "REQUIRED",
"name": "fare_amount",
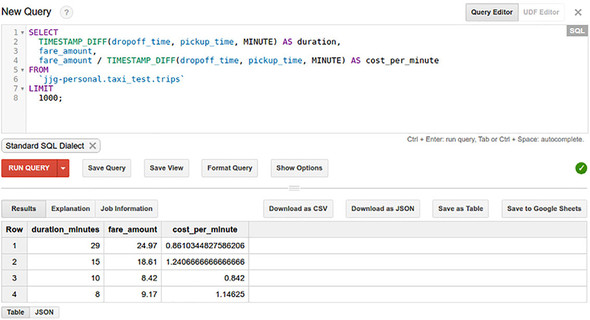
"type": "FLOAT"BigQuery will immediately create the table with the schema you defined and will create a load data job under the hood.Check on it by running a SQL query.

}
]SELECT
TIMESTAMP_DIFF(dropoff_time, pickup_time, MINUTE) AS duration_minutes,
fare_amount,
fare_amount / TIMESTAMP_DIFF(dropoff_time, pickup_time, MINUTE) AS
cost_per_minute
FROM
`your-project-id-here.taxi_test.trips`
LIMIT
1000;
should show how much each trip cost on a per-minute basis,
Streaming data into BigQuery
Want your application to generate new rows that you can search over?
BigQuery calls streaming ingestion or streaming data, and it refers specifically to sending lots of single data points into BigQuery over time rather than all at once.
Point at the table you want to add data to and (in Node.js) use the insert() method.
const BigQuery = require('@google-cloud/bigquery');
const bigquery = new BigQuery({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
const dataset = bigquery.dataset('taxi_test');
const table = dataset.table('trips');
const addTripToBigQuery = (trip) => {
return table.insert({
pickup_time: trip.pickup_time.getTime() / 1000,
dropoff_time: trip.dropoff_time.getTime() / 1000,
fare_amount: trip.fare_amount
});
}
Make sure you don’t load the same row twice.
No way to enforce a uniqueness constraint.
BigQuery can accept a unique identifier called insertId, which acts as a way of de-duplicating rows as they’re inserted.
If BigQuery has seen the ID before, it’ll treat the rows as already added and skip adding them.
const uuid4 = require('uuid/v4');
const BigQuery = require('@google-cloud/bigquery');
const bigquery = new BigQuery({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
const dataset = bigquery.dataset('taxi_test');
const table = dataset.table('trips');
const addTripToBigQuery = (trip) => {
const uuid = uuid4();
return table.insert({
json: {
pickup_time: trip.pickup_time.getTime() / 1000,
dropoff_time: trip.dropoff_time.getTime() / 1000,
fare_amount: trip.fare_amount
},
insertId: uuid
}, {raw: true});
}
Note that you’re using a random insert ID because a deterministic one (such as a hash) may disregard identical but non duplicate data.
19.2.3. Exporting datasets
They take data out of BigQuery and drop it into Cloud Storage as comma-separated, new-line separated JSON, or Avro.
19.3. Understanding pricing
Like many of the services on Google Cloud Platform, BigQuery follows the “pay for what you use” pricing model. But it’s a bit unclear exactly how much you’re using in a system like BigQuery, so let’s look more closely at the different attributes that cost money. With BigQuery, you’re charged for three things:
Storage of your data
Inserting new data into BigQuery (one row at a time)
Querying your data
Summary
BigQuery acts like a SQL database that can analyze terabytes of data incredibly quickly by allowing you to spike and make use of thousands of machines at a moment’s notice.
Although BigQuery supports many features of OLTP databases, it doesn’t have transactions or uniqueness constraints, and you should use it as an analytical data warehouse, not a transactional database.
Although data in BigQuery is mutable, the lack of uniqueness constraints means it’s not always possible to address a specific row, so you should avoid doing so—for example, don’t do UPDATE ... WHERE id = 5.
When importing or exporting data from BigQuery, GCS typically acts as an intermediate place to keep the data.
No comments:
Post a Comment