Chapter 5. Cloud Datastore: document storage
his chapter covers
What’s document storage?
What’s Cloud Datastore?
Interacting with Cloud Datastore
Deciding whether Cloud Datastore is a good fit
Key distinctions between hosted and managed services
What’s document storage?
What’s Cloud Datastore?
Interacting with Cloud Datastore
Deciding whether Cloud Datastore is a good fit
Key distinctions between hosted and managed services
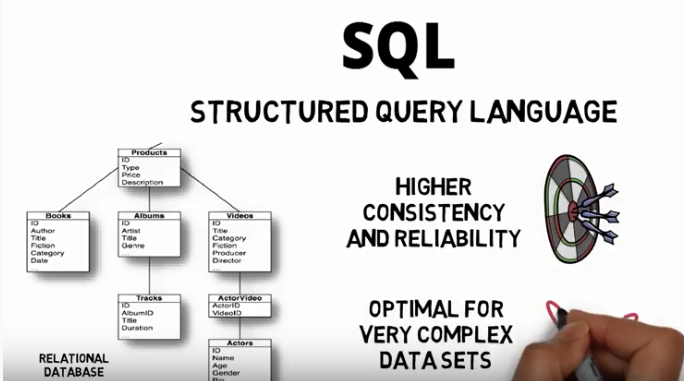
Document storage is a form of non relational storage that happens to be different
conceptually from the relational databases
Thinking of tables containing rows and keeping all of your data in a rectangular grid
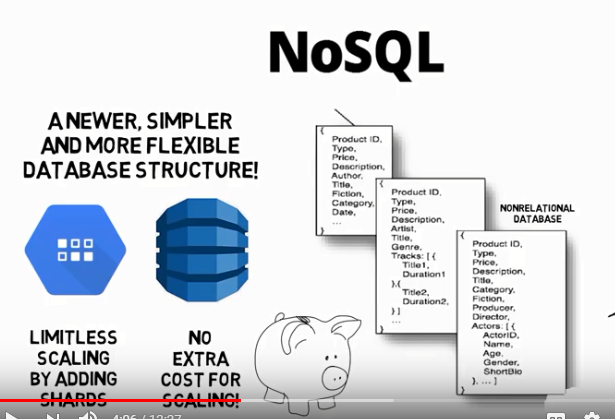
Document database thinks in terms of collections and documents.
Arbitrary sets of key-value pairs
Must have in common is the document type
Document database, you might have an Employees collection, which might contain two
documents:
{"id": 1, "name": "James Bond"}
{"id": 2, "name": "Ian Fleming", "favoriteColor": "blue"}
traditional table of similar data
Table 5.1. Grid of employee records
Table 5.2. Jagged collection of employees
SELECT * FROM Employees WHERE favoriteColor != "blue"
in some document storage systems the answer to this query is an empty set
reason is that a missing property isn’t the same thing as a property with a null value,
only documents considered are those that explicitly have a key called favoriteColor.
systems were designed with a focus on large-scale storage.
That all queries were consistently fast, the designers had to trade away advanced features
like joining related data
Things like lookups by a single key and simple scans through the data, but nowhere near
as full-featured as a traditional SQL database.
5.1. What’s Cloud Datastore?
Cloud Datastore is a highly scalable NoSQL database for your applications.
Cloud Datastore automatically handles sharding and replication, providing you with a
highly available and durable database that scales automatically to handle your
applications load. Cloud Datastore provides a myriad of capabilities such as
ACID transactions, SQL-like queries, indexes, and much more.
(Sharding is a type of database partitioning that separates very large databases the into
smaller, faster, more easily managed parts called data shards. The word shard means a
small part of a whole.
Fast and highly Scalable
Focus on building your applications without worrying about provisioning and load
anticipation. Cloud Datastore scales seamlessly and automatically with your data,
allowing applications to maintain high performance as they receive more traffic
Diverse data types
Cloud Datastore supports a variety of data types, including integers, floating-point
numbers, strings, dates, and binary data, among others.
First launched as the default way to store data in Google App Engine
Stand-alone storage system as part of Google Cloud Platform.
Designed to handle large-scale data.
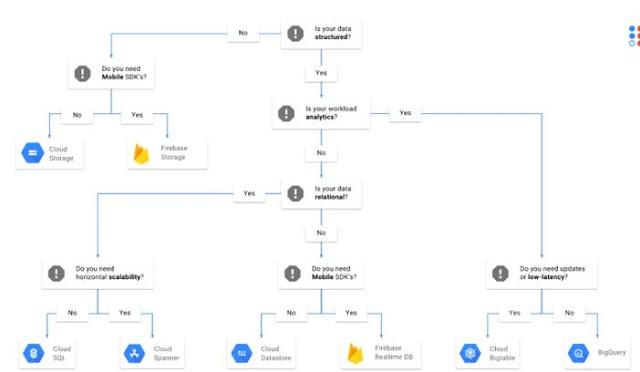

5.1.1. Design goals for Cloud Datastore
Large-scale storage system makes for a great example: Gmail
Data locality
Mail database would need to store all email for all accounts, you wouldn’t need to
search across multiple accounts.
Concept of where to put data is called data locality.
Datastore is designed in a way that allows you to choose which documents live near
other documents by putting them in the same entity group.
Result-set query scale
Frustrating if your inbox got slower as you receive more email.
Index emails as they arrive so that when you want to search your inbox,
Would be proportional only to the number of matching emails (not the total number of emails).
This idea of making queries as expensive, with regards to time, as the
number of results is sometimes referred to as scaling with the size of the result set.
Datastore uses indexing to accomplish this, query has 10 matches, it’ll take the same
amount of time regardless of whether you have 1 GB or 1 PB of email data.
Automatic replication
The fact that sometimes servers die, disks fail, and networks go down.
Email data in lots of places so it’s always available.
Data written should be replicated automatically to many physical servers.
Email is never on a single computer with a single hard drive. Instead, each email is
distributed across lots of places.
Google’s underlying storage systems are well suited to this requirement, and Cloud
Datastore takes care of it.

5.1.2. Concepts
How they fit together
Keys
The idea of a key, which is what Cloud Datastore uses to represent a unique identifier for anything that
has been stored.
Relational database world is the unique ID you often see as the first column in tables,
but Datastore keys have two major differences from table IDs.
Datastore doesn’t have an identical concept of tables
Datastore’s keys contain both the type of the data and the data’s unique identifier
Employee data in MySQL, the typical pattern is to create a table called employees and have a column in that table called id that’s a unique integer.
Rather than creating a table and then inserting a row, it happens all in one step:
you insert some data where the key is Employee:1. The type of the data here
(Employee) is referred to as the kind.
Two keys have the same parent, they’re in the same entity group
Parent keys are how you tell Datastore to put data near other data. (Give them the same
parent!)
You might want to nest sub entities inside each other.
Keys can refer to multiple kinds in their path or the hierarchy, and the kind (type) of the
data is the kind of the bottom-most piece.
Hierarchy
Store your employee records as children of the company they work for, which could be
Company:1:Employee:2
The kind of this key is Employee
The parent key is Company:1 (whose kind is Company)
Key refers to employee #2, and because of its parent (Company:1
Stored near all other employees of the same company; for example,
Company:1:Employee:44 will be nearby.
Can specify keys as strings, such as Company:1:Employee:jbond or Company:apple.com:Employee:stevejobs.

Entities
Primary storage concept in Cloud Datastore is an entity
An entity is nothing more than a collection of properties and values combined with a
unique identifier called a key
An entity can have properties of all the basics, also known as primitives, such as
Booleans (true or false)
Strings (“James Bond”)
Integers (14)
Floating-point numbers (3.4)
Dates or times (2013-05-14T00:01:00.234Z)
Binary data (0x0401)
{
"__key__": "Company:apple.com:Employee:jonyive",
"name": "Jony Ive",
"likesDesign": true,
"pets": 3
}
Datastore exposes some more advanced types
Lists, which allow you to have a list of strings
Keys, which point to other entities
Embedded entities, which act as subentities
{
"__key__": "Company:apple.com:Employee:jonyive",
"manager": "Company:apple.com:Employee:stevejobs",
"groups": ["design", "executives"],
"team": {
"name": "Design Executives",
"email": "design@apple.com"
}
}
Reference to another key is as close as you can get to the concept of foreign keys.
In the context of relational databases, a foreign key is a field (or collection of fields)
in one table that uniquely identifies a row of another table or the same table.
No way to enforce that a reference is valid, so you have to keep references up to date;
for example, if you delete the key, update the reference.
Lists of values typically aren’t supported in relational databases
In Datastore, if that structured data doesn’t need its own row in a table, you can embed
that data directly inside another entity using embedded entities.
Put the contents of the function inline rather than naming them as a function and calling
them by name.

Operations
Things you can do to an entity. The basic operations are
get—Retrieve an entity by its key.
put—Save or update an entity by its key.
delete—Delete an entity by its key.
All of these operations require the key for the entity
Omit the ID portion of the key in a put operation, Datastore will generate one
automatically for you.
Indexes and queries
Typical database, a query is nothing more than a SQL statement, such as
SELECT * FROM employees.
Using GQL (a query language much like SQL).
Datastore uses indexes to make a query possible (table 5.3).
Table 5.3. Queries and indexes, relational vs Datastore
Creating an index that stays up to date whenever information changes and that you can
scan through to find matching emails.
Index is nothing more than a specially ordered and maintained data set to make querying
fast.
Table 5.4. An index over the sender field
Index pulls out the sender field from emails and allows you to query over all emails with a certain sender value.
When the query finishes, all matching results have been found.
5.1.3. Consistency and replication
Distributed storage system for something like Gmail needs to meet two key requirements:
to be always available and to scale with the result set.
One protocol that Cloud Datastore happens to use involves something called a two-phase
commit.
You break the changes you want saved into two phases: a preparation phase and a
commit phase.
Preparation phase, you send a request to a set of replicas, describing a change and asking
the replicas to get ready to apply it.
Confirm that they’ve prepared the change, you send a second request instructing all
replicas to apply that change.
This second (commit) phase is done asynchronously, where some of those changes may
hang around in the prepared but not yet applied state.
Arrangement leads to eventual consistency when running broad queries where the entity
or the index entry may be out of date.
First push a replica to execute any pending commits of the resource and then run the
query, resulting in a strongly consistent result.
Maintaining entities and indexes in a distributed system is a much more complicated task
Datastore would have two options:
Update the entity and the indexes everywhere synchronously, confirming the operation
will take an unreasonably long time
Update the entity itself and the indexes in the background, keeping request latency much
lower.
Datastore chose to update data asynchronously to make sure that no matter how many
indexes you add, the time it takes to save an entity is the same.
Create or update the entity.
Determine which indexes need to change as well.
Tell the replicas to prepare for the change.
Ask the replicas to apply the change when they can.
Ensure all pending changes to the affected entity group are applied.
Execute the query.
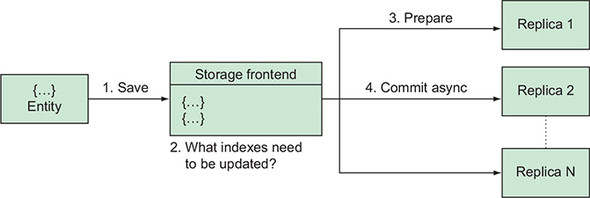
Datastore uses these indexes to make sure your query runs in time that’s proportional to
the number of matching results found.
Send the query to Datastore.
Search the indexes for matching keys.
For each matching result, get the entity by its key in an eventually consistent way.
Return the matching entities.
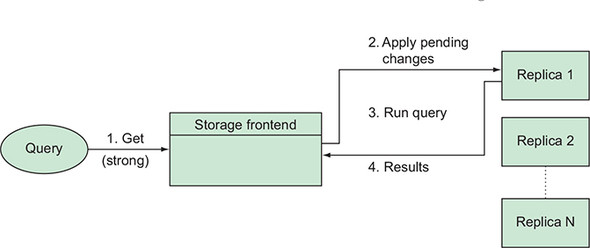
The indexes are updated in the background, so there’s no real guarantee regarding when the indexes will be updated.
Eventual consistency, which means that eventually your indexes will be up to date (consistent) with the data you have stored in your entities.
Listing 5.1. Example Employee entity
{
"__key__": "Employee:1",
"name": "James Bond",
"favoriteColor": "blue"
}
SELECT * FROM Employee WHERE favoriteColor = "blue"
If the indexes haven’t been updated yet (they will eventually), you won’t get this employee back in the result.
Ask specifically for the entity
get(Key(Employee, 1))
Eventually consistent, specifically because the indexes that Datastore uses to find those
entities are updated in the background.
Change this employee’s favorite color

Data is written to Datastore in objects known as entities. Each entity has a key that uniquely identifies it. An entity can optionally designate another entity as its parent; the first entity is a child of the parent entity. The entities in the data store thus form a hierarchically-structured
space similar to the directory structure of a file system.
For detailed information, see Structuring Data for Strong Consistency.
Listing 5.2. Employee entity with a different favorite color
{
"__key__": "Employee:1",
"name": "James Bond",
"favoriteColor": "red"
}
You may see different results
Table 5.6. Summary of the different possible results
You may see different results, three possibilities are:
The query still sees the employee as matching the query (favoriteColor = blue),
and correctly so, so it ends up in the results.
The query still sees the employee as matching the query (favoriteColor = blue), so it ends up in the results, even though the entity doesn’t actually match! (favoriteColor = red)
Combining querying with data locality to get strong consistency.
5.1.4. Consistency with data locality
Data locality as a tool for putting many pieces of data near each other.
Eventual consistency (that your queries run over indexes rather than your data, and those
indexes are eventually updated in the background).
entity group, defined by keys sharing the same parent key
Query over a bunch of entities that all have the same parent key, your query will be
strongly consistent.
Telling Datastore where you want to query over in terms of the locality gives it a specific
range of keys to consider.
Queries inside a single entity group are strongly consistent (not eventually consistent)
Combining querying with data locality to get strong consistency.
Query over a bunch of entities that all have the same parent key, your query will
be strongly consistent.
Where you want to query over in terms of the locality gives it a specific range of keys to
consider.
Pending operations in that range of keys are fully committed prior to executing the query.
All Apple employees who have blue as their favorite color.
Knows exactly which keys could be in the result set.
First make sure no operations involving those keys are pending.
{
"__key__": "Company:apple.com:Employee:jonyive",
"name": "Jony Ive",
"favoriteColor": "blue"
}
update to red
{
"__key__": "Company:apple.com:Employee:jonyive",
"name": "Jony Ive",
"favoriteColor": "red"
}
Query over all Apple employee
SELECT * FROM Employees WHERE favoriteColor = "blue" AND
__key__ HAS ANCESTOR Key(Company, 'apple.com')
Query is limited to a single entity group
Results will always be consistent with the data,
Single entity group can only handle a certain number of requests simultaneously.
Trading off eventual consistency and getting pretty low throughput overall in return.
5.2. Interacting with Cloud Datastore
Enable it in the Cloud Console.

SELECT DATASTORE MODE

CHOOSE A REGION

READY TO CREATE ENTITY
Go back to the To-Do List example
Start by creating the TodoList entity.
You’ll first create some data.
Rather than defining a schema.
Typical for non-relational storage
Blue Create Entity button
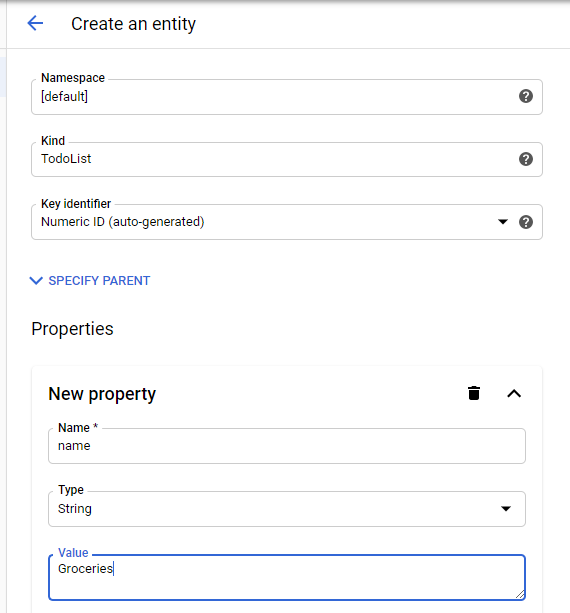
Leave your entity in the [default] namespace
Make it a TodoList kind
Datastore automatically assign a numerical ID.
Give your TodoList entity a name.
Add Property button
Name of the property to name
Property type set to String
Fill in the value of the property called Groceries
Leave the property indexed (marked by the check box).
Click Create, and you should see a newly created TodoList entity

Listing 5.5. Querying Cloud Datastore for all TodoList entities
Moving away from node.js to python
#!/usr/bin/env python
# Copyright 2016 Google Inc. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
def run_quickstart():
# [START datastore_quickstart]
# Imports the Google Cloud client library
from google.cloud import datastore
# Instantiates a client
datastore_client = datastore.Client()
# The kind for the new entity
kind = 'Task'
# The name/ID for the new entity
name = 'sampletask1'
# The Cloud Datastore key for the new entity
task_key = datastore_client.key(kind, name)
# Prepares the new entity
task = datastore.Entity(key=task_key)
task['description'] = 'Buy milk'
# Saves the entity
datastore_client.put(task)
print('Saved {}: {}'.format(task.key.name, task['description']))
# [END datastore_quickstart]
if __name__ == '__main__':
run_quickstart()
5.3. Backup and restore
Cloud Datastore backups are a bit unusual in that they’re not exactly backups in the
sense that you’ve gotten used to them.
Datastore’s backup ability is more of an export that’s able to take a bunch of data from
a regular Datastore query and ship it off to a Cloud Storage bucket.
Data exported to Cloud Storage could be equally inconsistent.
Exports are not a snapshot taken at a single point in time.
Instead, they’re more like a long-exposure photograph of your data.
Disable Datastore writes beforehand and then re-enable them once the export completes.
Need a Cloud Storage bucket.
Place that’ll hold your exported data,
$ gsutil mb -l US gs://my-data-export
Creating gs://my-data-export/...
Disable writes to your Datastore instance via the Cloud Console, using the Admin tab
in the Datastore section

$
5.4. Understanding pricing
Google determines Cloud Datastore prices based on two things: the amount of data you store and the number of operations you perform on that data. Let’s look at the easy part first: storage.
5.4.1. Storage costs
Measured in GB, costing $0.18 per GB per month
Total storage size for billing purposes of a single entity includes the kind name
(for example, Person ), the key name (or ID), all property names
(for example, favoriteColor), and 16 extra overhead bytes.
Properties have simple indexes created, where each index entry includes the kind name,
the key name, the property name, the property value, and 32 extra overhead bytes.
ng names (indexes, properties, and keys) tend to explode in size, so you’ll have far more
total data than the actual data stored.
5.4.2. Per-operation costs
Any requests that you send to Cloud Datastore,
Table 5.7. Operation pricing breakdown
Retrieve 100,000 of your entities, your bill will be 6 cents
5.5. When should I use Cloud Datastore?

Two places where Datastore shines are durability and throughput,
5.5.1. Structure
Cloud Datastore excels at managing semistructured data where attributes have types
No single schema across all entities (or documents) of the same kind.
Datastore also allows you to express the locality of your data using hierarchical keys
(where one key is prefixed with the key of its parent).
Segment data between units of isolation.
Desire to segment data between units of isolation.
Enables automatic replication of your data, is what allows it to be so highly available as
a storage system.
Queries across all the data will be eventually consistent.
5.5.2. Query complexity
Nonrelational storage system.
Cloud Datastore doesn’t support the typical relational aspects (for example, the JOIN operator).
Allow you to store keys that act as pointers to other stored entities,
No referential integrity and no ability to cascade or limit changes involving referenced
entities.
Referential integrity refers to the accuracy and consistency of data within a relationship.
In relationships, data is linked between two or more tables . This is achieved by having
the foreign key (in the associated table) reference a primary key value (in the primary –
or parent – table).
Delete an entity in Cloud Datastore, anywhere you pointed to that entity from elsewhere
becomes an invalid reference.
Certain queries require that you have indexes to enable them.
Limitations are the consequence of the structural requirements that went into designing
Cloud Datastore, whereas other limitations enable consistent performance for all queries.
5.5.3. Durability
Because Megastore was built on the premise that you can never lose data, everything
is automatically replicated and not considered saved until saved in several places.
Datastore handles this entirely on its own, meaning that the only setting for durability
is as high as possible.
Global queries being only eventually consistent.
Data needs to replicate to several places before being called saved.
5.5.4. Speed (latency)
Compared to many in-memory storage systems
Cloud Datastore won’t be as fast for the simple reason that even SSDs are slower than
RAM.
Relational database system like PostgreSQL or MySQL, Cloud Datastore will be in the
same ballpark.
As your SQL database gets larger or receives more requests at the same time,
it’ll likely get slower.
Cloud Datastore’s latency stays the same regardless of the level of concurrency.
Cloud Datastore certainly won’t be blazing fast like in-memory NoSQL storage systems,
but it’ll be on par with other relational databases .
5.5.5. Throughput
Accommodate as much traffic as you care to throw at it.
The pessimistic locking that comes with relational databases like MySQL doesn’t apply.
Able to scale up to many concurrent write operations.
Adding more servers on Google’s side to keep up.
5.5.6. Cost
Storing a few gigabytes, your total cost of storage and querying could be around
$50 a month.
Add more and more data, and query that data more and more frequently, overall costs
can skyrocket—primarily because of indexes.
Benefit of never worrying that your data will be unavailable.
5.5.7. Overall
To-Do ListTable 5.8. To-Do List application storage needs
Bit of overkill on the scalability side.
To-Do List app could become something enormous, then Datastore is a safe bet to go
with because it means that scaling to handle tons of traffic is something you don’t need
to worry about too much.
E*Exchange
Table 5.9. E*Exchange storage needs
Datastore is probably not the best fit for E*Exchange if used on its own
doesn’t enforce strict schema requirements
E*Exchange wants clear validation of any data entering the system.
Enforce that schema in your application rather than relying on the database.
So although it’s possible to do it, it’s not built into Datastore.
Can’t do extremely complex queries,
Eventually consistent queries will be challenging to design around for a system
that requires highly accurate and up-to-date information like E*Exchange.
InstaSnap
Table 5.10. InstaSnap storage needs
InstaSnap is the single-query latency - needs to be extremely fast.
in conjunction with some sort of in-memory cache
InstaSnap is a pretty solid fit because of the relatively simple queries combined with the
enormous throughput requirements. As a matter of fact, SnapChat (the real app) uses
Datastore as one of its primary storage systems.
5.5.8. Other document storage systems
Table 5.11. Brief comparison of document storage systems
Possible to configure systems like HBase and MongoDB for high availability,
when that happens, cost will go up.
Summary
Document storage keeps data organized as heterogeneous (jagged) documents rather than homogeneous rows in a table.
Using document storage effectively may involve duplicating data for easy access (denormalizing).
Document storage is great for storing data that may grow to huge sizes and experience huge amounts of traffic, but it comes at the cost of not being able to do fancy queries (for example, joins that you do in SQL).
Cloud Datastore is a fully managed storage system with automatic replication, result-set query scale, full transactional semantics, and automatic scaling.
Cloud Datastore is a good fit if you need high scalability and have relatively straightforward queries.
Cloud Datastore charges for operations on entities, meaning the more data you interact with, the more you pay.
Data is written to Datastore in objects known as entities. Each entity has a key that uniquely identifies it. An entity can optionally designate another entity as its parent; the first entity is a child of the parent entity. The entities in the data store thus form a hierarchically-structured space similar to the directory structure of a file system. For detailed information, see Structuring Data for Strong Consistency.
Document storage keeps data organized as heterogeneous (jagged) documents rather than homogeneous rows in a table.
Using document storage effectively may involve duplicating data for easy access (denormalizing).
Document storage is great for storing data that may grow to huge sizes and experience huge amounts of traffic, but it comes at the cost of not being able to do fancy queries (for example, joins that you do in SQL).
Cloud Datastore is a fully managed storage system with automatic replication, result-set query scale, full transactional semantics, and automatic scaling.
Cloud Datastore is a good fit if you need high scalability and have relatively straightforward queries.
Cloud Datastore charges for operations on entities, meaning the more data you interact with, the more you pay.


No comments:
Post a Comment