Chapter 20. Cloud Dataflow: large-scale data processing
What do we mean by data processing?
What is Apache Beam?
What is Cloud Dataflow?
How can you use Apache Beam and Cloud Dataflow together to process large sets of data?
Data processing, we tend to mean taking a lot of data (measured in GB at least), potentially combining it with other data, and ending with either an enriched data set of similar size or a smaller data set that summarizes some aspects of the huge pile of data.
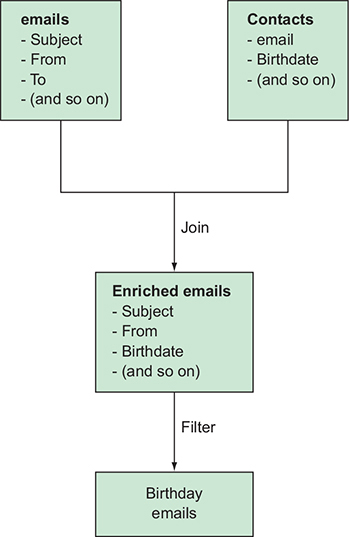
Taking large chunks of data and combining them with other data (or transforming them somehow) to come out with a more meaningful set of data can be valuable
Processing one chunk of data into a different chunk of data, you also can think of data processing as a way to perform streaming transformations over data while it’s in flight.
Intercept emails as they arrive and enrich them one at a time.

Rely on a stream, you could increment a counter to keep count whenever new emails arrive.
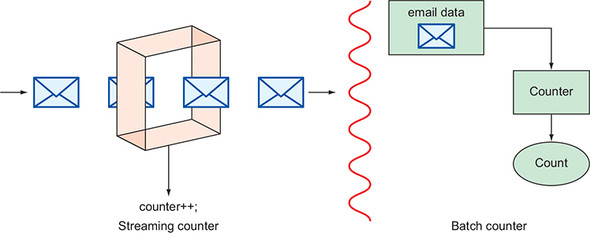
You can express these things in lots of ways, but we’ll look specifically at an open source project called Apache Beam.
20.1. What is Apache Beam?
Ability to transform, enrich, and summarize data can be valuable (and fun)
“get some data from somewhere, combine this data with this data, and add this new field on each item by running this calculation,”
For handling data processing pipelines, Apache Beam fits the bill quite well.
Beam is a framework with bindings in both Python and Java that allows you to represent a data processing pipeline with actions for inputs and outputs as well as a variety of built-in data transformations.
20.1.1. Concepts
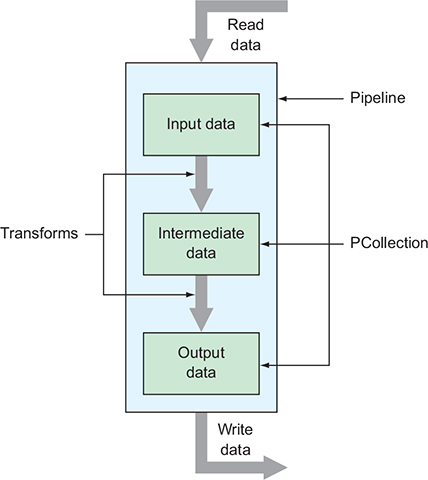
Key concepts we’ll look at include the high-level container (a pipeline), the data that flows through the pipeline (called PCollections), and how you manipulate data along the way (using transforms).
Pipelines
A pipeline refers to the high-level container of a bunch of data processing operations.
Encapsulate all of the input and output data as well as the transformation steps that manipulate data from the input to the desired output.
A pipeline is a directed acyclic graph (sometimes abbreviated to DAG)—it has nodes and edges that flow in a certain direction and don’t provide a way to repeat or get into a loop.
Clearly flows in a single direction and can’t get into a loop.

Pipelines themselves can have lots of configuration options (such as where the input and output data lives), which allows them to be somewhat customizable.
Beam pipelines are directed acyclic graphs—they’re things that take data and move it from some start point to some finish point without getting into any loops.
PCollections
The nodes in your graph or the data in your pipeline, act as a way to represent intermediate chunks or streams of data as they flow through a pipeline.
Data could be of any size, ranging from a few rows that you add to your pipeline code to an enormous amount of data distributed across lots of machines.
Infinite stream of incoming data that may never end.
Temperature sensor that sends a new data point of the current temperature every second.
PCollection is bounded, you may not know the exact size, but you do know that it does have a fixed and finite size (such as 10 billion items).
Unbounded PCollection is one that has no predefined finite size and may go on forever.
Stream of data that’s being generated in real time.
You always create a PCollection within a pipeline, and it must stay within that pipeline.
PCollections themselves are immutable.
You can’t change its data.
You can create new PCollections by transforming existing ones.
You can continue asking for more data from them, but can’t necessarily jump to a specific point in the PCollection.
Transforms
Take chunks of input data and mutate them into chunks of output data.
Take PCollections and turn them into other PCollections.
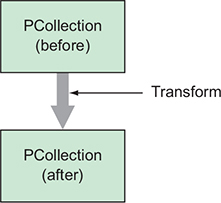
Following are all examples of transforms built in to Beam.
Filter out unwanted data that you’re not interested.
Split the data into separate chunks.
Group the data by a certain property.
Join together two (or more) chunks of data.
Enrich the data by calculating something new.
One PCollection as input and another as output, it’s entirely possible that a transform will have more than one input (or more than one output).
When you apply a transformation to an existing PCollection, you create a new one without destroying the existing one that acted as the data source.
New PCollection as containing the transformed data.
Pipeline runners
You can keep the definition of a pipeline separate from the execution of that pipeline.
Take the same pipeline you defined using Beam and run it across a variety of execution engines.
ORM (object-relational mapping) that you implement with SQL Alchemy in Python or Hibernate in Java.
Define your resources and interact with them as objects in the same language (for example, Python), and under the hood the ORM turns those interactions into SQL queries for a variety of databases (such as MySQL and PostgreSQL).
Simplest option being the DirectRunner. This runner is primarily a testing tool that’ll execute pipelines on your local machine.
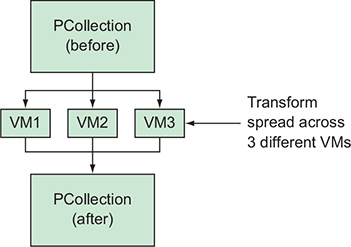
Pipeline runners will do their best to execute computations on as few machines as possible.
The pipeline runner will likely land on the division of labor that results in the shortest total time to execute the pipeline.
20.1.2. Putting it all together
Three basic concepts (pipelines, PCollections, and transforms) you can build some cool things.
Digital copy of some text and want to count the number of words that start with the letter a.
Could instead use Apache Beam to define a pipeline that would do this for you, which would allow you to spread that work across lots of computers and still get the right output.
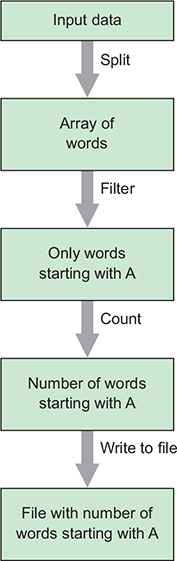
Use multiple steps to take some raw input data and transform it into the output you’re interested in.
import re
import apache_beam as beam
with beam.Pipeline() as pipeline:
(pipeline
| beam.io.ReadFromText(input_file)
| 'Split' >> (beam.FlatMap(lambda x:
re.findall(r'[A-Za-z\']+', x))
.with_output_types(unicode))
| 'Filter' >> beam.Filter(lambda x: x.lower()
.startswith('a'))
| 'Count' >> beam.combiners.Count.Globally()
| beam.io.WriteToText(output_file)
)
Apache Beam’s Python bindings, you rely on the pipe operator, as you would in a Unix-based terminal, to represent data flowing through the transformations.
20.2. What is Cloud Dataflow?
Use Apache Beam to define pipelines that are portable across lots of pipeline runners.
Lots of options to choose from when it comes time to run Beam pipelines. Google Cloud Dataflow is one of the many options available
You can submit your pipeline to execute without any other prior configuration.
Cloud Dataflow is part of Google Cloud Platform, it has the ability to stitch together lots of other services.

Google’s systems handle all of this coordination across the various Google Cloud Platform resources for you.
20.3. Interacting with Cloud Dataflow
20.3.1. Setting up
enable the Cloud Dataflow API

make sure you have Apache Beam installed locally. To do this, you can use pip, which manages packages for Python. Although the package itself is called apache-beam, you want to make sure you get the Google Cloud Platform extras for the package.
$ pip install apache-beam[gcp]
$ gcloud auth application-default login
$ gsutil mb -l us gs://your-bucket-id-here
Creating gs://your-bucket-id-here/...
20.3.2. Creating a pipeline
import argparse
import re
import apache_beam as beam
from apache_beam.options import pipeline_options
PROJECT_ID = '<your-project-id-here>'
BUCKET = 'dataflow-bucket'
def get_pipeline_options(pipeline_args):
pipeline_args = ['--%s=%s' % (k, v) for (k, v) in {
'project': PROJECT_ID,
'job_name': 'dataflow-count',
'staging_location': 'gs://%s/dataflow-staging' % BUCKET,
'temp_location': 'gs://%s/dataflow-temp' % BUCKET,
}.items()] + pipeline_args
options = pipeline_options.PipelineOptions(pipeline_args)
options.view_as(pipeline_options.SetupOptions).save_main_session = True
return options
def main(argv=None):
parser = argparse.ArgumentParser()
parser.add_argument('--input', dest='input')
parser.add_argument('--output', dest='output',
default='gs://%s/dataflow-count' % BUCKET)
script_args, pipeline_args = parser.parse_known_args(argv)
pipeline_opts = get_pipeline_options(pipeline_args)
with beam.Pipeline(options=pipeline_opts) as pipeline:
(pipeline
| beam.io.ReadFromText(script_args.input)
| 'Split' >> (beam.FlatMap(lambda x: re.findall(r'[A-Za-z\']+', x))
.with_output_types(unicode))
| 'Filter' >> beam.Filter(lambda x: x.lower().startswith('a'))
| 'Count' >> beam.combiners.Count.Globally()
| beam.io.WriteToText(script_args.output)
)
if __name__ == '__main__':
main()
20.3.3. Executing a pipeline locally
$ echo "You can avoid reality, but you cannot avoid the consequences of
avoiding reality." > input.txt
$ python counter.py --input="input.txt" \
--output="output-" \
--runner=DirectRunner
$ ls output-*
output--00000-of-00001
$ cat output--00000-of-00001
3
$ python -c "print (raw_input() + '\n') * 10**5" < input.txt > input-10e5.txt
$ wc -l input-10e5.txt
100001 input-10e5.txt
$ du -h input-10e5.txt
7.9M input-10e5.txt
$ python counter.py --input=input-10e5.txt --output=output-10e5- \
--runner=DirectRunner
$ cat output-10e5-*
300000
20.3.4. Executing a pipeline using Cloud Dataflow
$ gsutil -m cp input-10e5.txt gs://dataflow-bucket/input-10e5.txt
$ python counter.py \
--input=gs://dataflow-bucket/input-10e5.txt \
--output=gs://dataflow-bucket/output-10e5- \
--runner=DataflowRunner
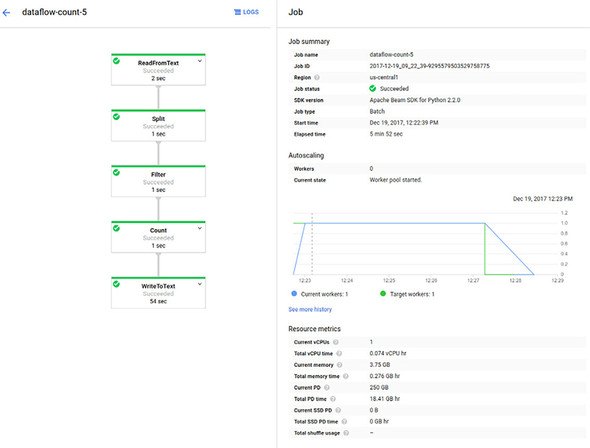
20.4. Understanding pricing
Like many compute-based products (such as Kubernetes Engine or Cloud ML Engine), Cloud Dataflow breaks down the cost of resources by a combination of computation (CPU per hour), memory (GB per hour), and disk storage (GB per hour).
Summary
When we talk about data processing, we mean the idea of taking a set of data and transforming it into something more useful for a particular purpose.
Apache Beam is one of the open source frameworks you can use to represent data transformations.
Apache Beam has lots of runners, one of which is Cloud Dataflow.
Cloud Dataflow executes Apache Beam pipelines in a managed environment, using Google Cloud Platform resources under the hood.
No comments:
Post a Comment