Chapter 18. Cloud Machine Learning Engine: managed machine learning
This chapter covers
What is machine learning?
What are neural networks?
What is TensorFlow?
What is Cloud ML Engine?
Creating and deploying your own ML model
18.1. What is machine learning?
Machine learning and artificial intelligence are enormous topics with quite a lot of ongoing research.
ML APIs, such as the speech recognition example

System that can be trained with some data and then make predictions based on that training.
Different from how we typically build software.
Programmer translates that goal into explicit instructions or “rules” for the computer to follow.
Machine learning involves the idea of the computer figuring out the rules on its own rather than by having someone teach them explicitly.
Double a value, you’d take that goal (“multiply by two”) and write the program console.log(input * 2).
Machine learning, you’d instead show the system a bunch of inputs and desired outputs (such as 2 → 4 and 40 → 80), and using those examples, the system would be responsible for figuring out the rules on its own.
Make predictions about what 5 * 2 is without having seen that particular example before by assuming 5 is the input and making a prediction about 5 → ?.
Systems capable of “learning” using several methods.
Most interest recently is modeled after the human brain.
18.1.1. What are neural networks?
Fundamental components in modern machine learning systems is called a neural network.
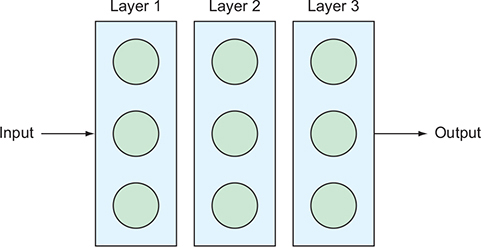
All of the heavy lifting of both learning and predicting and can vary in complexity from super simple (like the one shown in figure 18.2) to extremely complex (like your brain).
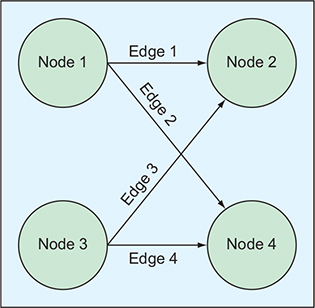
A neural network is a directed graph containing a bunch of nodes.
Connected to one another along edges.
Each line has a certain weight.
The directed part means that things flow in a single direction.
Line weights determine how much of an input signal is transmitted into an output signal.
How much the value of one node affects the value of another node that it’s connected to.
Nodes themselves are organized into layers.
First layer accepting a set of input values.
Last layer representing a set of output values.
Neural network works by taking these input values and using the weights to pass those values from one layer to another.
Input can be manipulated bit by bit and end up completely different.
Where each node represents a person in the chain.
Weights on the edges between each node represent how well the next person can understand the previous person’s whispers.

Train a neural network by taking an input, sending it into the network to get an output.
Adjusting the weights based on how far off the output was from the expected output.
Make lots and lots of these adjustments for lots and lots of example data points, lots of times over and over, the network can get pretty good at making predictions for data that it hasn’t seen before.
Varying the weights between nodes throughout training.
Adjust values that are external to the training data.
Adjustments, called hyperparameters, are used to tune the system for a specific problem to get the best predictive results.
Typically come from heuristics as well as trial and error.
Understand the fundamental point (something takes input, looks at output, and makes adjustments).
Self-adjusting system and do something like figure out whether a cat is in an image?
18.1.2. What is TensorFlow?
TensorFlow is a machine-learning development framework that makes it easier to express machine-learning concepts in code rather than in scary mathematical equations.
Provides abstractions to track the different variables, utilities like matrix multiplication, neural network optimization algorithms, and various estimators and optimizers that give you control over how all of those adjustments are applied to the system itself during the learning period.
Bringing all the fancy math of neural networks and other machine-learning algorithms into code.
Sample data set called MNIST, which is a collection of images represented by handwritten numbers.
Each image is a square of 28 pixels, and each data point has the image itself as well as the number represented in the image.
Both handwritten numbers to use for training and a separate set to use when testing how well the model does using data it hasn’t seen before.
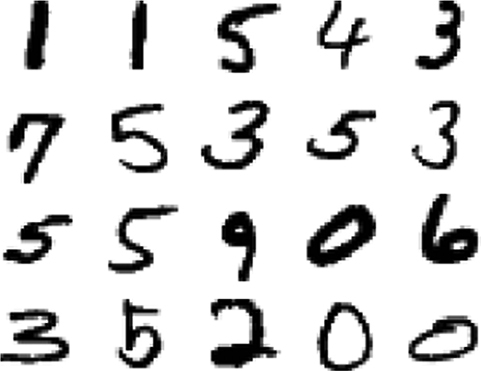
TensorFlow makes it easy to pull in these sample images, you’ll use them to build a model that can take a similar image and predict what number is written in the image.
Super-slimmed-down version of Cloud Vision’s text recognition API.
Rain on the sample training data and then use the evaluation data to test how effective your model is at identifying a number from an image that wasn’t used during the training.
===========================================================
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data/', one_hot=True)
# Learning model info
x = tf.placeholder(tf.float32, [None, 28*28])
weights = tf.Variable(tf.zeros([28*28, 10]))
bias = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x, weights) + bias)
# Cross entropy ("How far off from right we are")
y_ = tf.placeholder(tf.float32, [None, 10])
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y))
# Training
train_step = tf.train.GradientDescentOptimizer(0.5).
minimize(cross_entropy)
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
for _ in xrange(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
# Evaluation
correct_prediction = tf.equal(tf.argmax(y, 1),
tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
result = sess.run(accuracy,
feed_dict={x: mnist.test.images, y_: mnist.test.labels})
print('Simple model accuracy on test data:', result)
===========================================================
TensorFlow can be complicated, and this example doesn’t even use a deep neural network! If you were to run this script
===========================================================
$ python mnist.py
Successfully downloaded train-images-idx3-ubyte.gz
9912422 bytes.
Extracting MNIST_data/train-images-idx3-ubyte.gz
Successfully downloaded train-labels-idx1-ubyte.gz 28881 bytes.
Extracting MNIST_data/train-labels-idx1-ubyte.gz
Successfully downloaded t10k-images-idx3-ubyte.gz 1648877 bytes.
Extracting MNIST_data/t10k-images-idx3-ubyte.gz
Successfully downloaded t10k-labels-idx1-ubyte.gz 4542 bytes.
Extracting MNIST_data/t10k-labels-idx1-ubyte.gz
('Simple model accuracy on test data:', 0.90679997)
===========================================================
Recognize handwritten numbers with a 90% accuracy rate
Told it how to handle your input training data (which was an image of a number and the number), then gave it the correct answer (because all of the data is labeled), and it figured out how to make the predictions based on that. So what happens if you increase the number of iterations from 1,000 to 10,000?
Run again
python mnist.py
Extracting MNIST_data/train-images-idx3-ubyte.gz
Extracting MNIST_data/train-labels-idx1-ubyte.gz
Extracting MNIST_data/t10k-images-idx3-ubyte.gz
Extracting MNIST_data/t10k-labels-idx1-ubyte.gz
There are three things important to notice:
Because you already downloaded the MNIST dataset, you don’t download it again.
The accuracy went up by a couple of points (to 92%) by running more training iterations.
It took longer to run this script!
Change the number of iterations even further (say, to 100,000), you might get a slightly higher number (in my case it went up to 93%) but at the cost of the script taking much longer to execute.
How are you supposed to provide adequate training for your ML models, which will be far more complex than this example?
18.2. What is Cloud Machine Learning Engine?
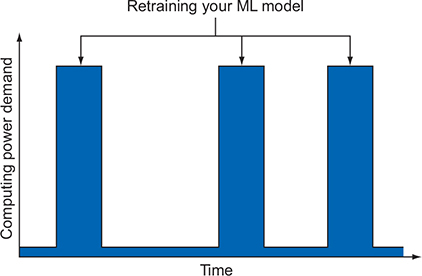
Training machine-learning models can start out being pretty quick, but because it’s such a computationally intensive process, doing more iterations or using a more complex machine-learning model could end up taking quite a bit of time to compute.
Data will probably be customized to individual users and change over time as users do new things. As the data evolves, your machine-learning model should evolve as well, which would require that you retrain your model to get the most up-to-date predictions.
Demand for resources .
You need a lot of power to retrain the model,
Cloud Machine Learning Engine
('Simple model accuracy on test data:', 0.92510003)
Cloud Machine Learning Engine.
Acting as a hosted service for your machine-learning models that can provide infrastructure to handle storage, training, and prediction.
ML Engine can also store and host trained models so that you can send your inputs to ML Engine and request that a particular model be used to calculate the predicted outputs.
Send Cloud ML Engine something like your TensorFlow script, which you can use to train the model, and after that model is trained, you can send inputs to the model and get a prediction for what number was written.
ML Engine allows you to turn your custom models into something more similar to the other hosted machine-learning APIs like the Vision API.
18.2.1. Concepts
Core concepts that allow you to organize your project’s machine-learning pieces so that they’re easy to use and manage.
Cloud ML Engine is a bit like App Engine in that you can run arbitrary machine-learning code, but you can also organize the code into separate pieces, with different versions as things evolve over time.
Models
A machine-learning model is sort of like a black-box container that conforms to a specific interface that offers two primary functions: train and predict.
Training the model based on a chunk of labeled images and then attempts to get predictions from some images it hasn’t seen before.
Idea behind using machine learning is to find the answers that you don’t already know.

(train and predict) must exist.
Models are designed to ingest data of a specific format. If you were to send data of other formats to the model (either for training or predicting purposes), the results would be undefined.
Earlier script that recognizes handwritten numbers, the model is designed to understand input data in the form of a grayscale bitmap image of a handwritten number. If you were to send it data in any other format (such as a color image, a JPEG image, or anything else), any results would be meaningless.
If invalid data (such as an unknown image format) was the input during a prediction request, you’d likely see a bad guess for the number drawn or an error.
Invalid data during the training process, you’d likely reduce the overall accuracy because the model would be training itself on data that doesn’t make much sense.
The contract for the model you built previously could be thought of as the black box.
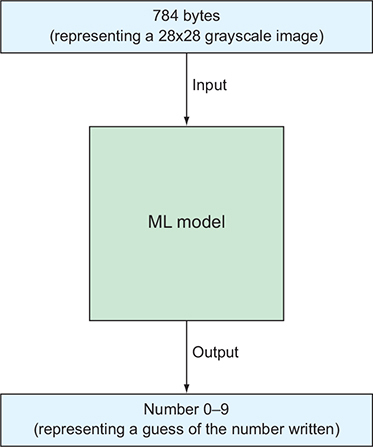
If the inputs or outputs change, the model itself is different, whereas if the model’s internal functionality fulfills the contract but uses different technology under the hood, the model may have different accuracy levels, but it still conceptually does the same job.
Versions
Like a Node.js package, App Engine service, or shared Microsoft Word document, Cloud ML models can support different versions as the inner workings of a model evolve over time.
Compare different versions against one another for things like cost or accuracy.

Ability to create many versions of a model allows you to try lots of things when building it and test which of the configurations results in the best predictions for your use case.
Cloud ML Engine uses Google Cloud Storage to track all of the data files that represent the model and also as a staging ground where you can put data for training the model.
How do you interact with these models? This is where jobs come into the picture.
Jobs
Ability to be trained and the ability to make predictions based on that training.
Amount of data involved in things like training can be exceptionally large.
A “job,” which is a way of requesting work be done asynchronously. After you start one of these jobs, you can check on the progress later and then decide what to do when it completes.
Some form of input (either training input or prediction input) that results in an output of the results, and it will run for as long as necessary to complete the work.
18.2.2. Putting it all together
ML Engine stores data in Cloud Storage
The underlying data for that model lives in Google Cloud Storage
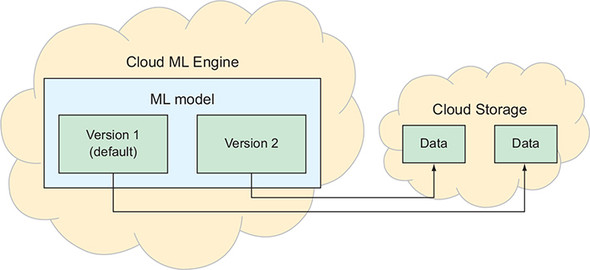
ML Engine using jobs, so to get model data stored in Cloud Storage, you’d use a training job
ML Engine to look for the training data somewhere in Cloud Storage.
Put the output job somewhere in Cloud Storage.

Upload the training data to Cloud Storage.
Create a job in ML Engine asking for that data to be used to train a version of your model.
Job (3) would take the training data from Cloud Storage and use it to train the new model version by running it through the model using the TensorFlow.
Store its output back on Cloud Storage so that you can use it for predicting.
End up with a trained model version in Cloud ML Engine with all the data needed being stored in Cloud Storage.
Ready to make predictions.

Start by uploading the data you want to make predictions on to Cloud Storage.
Create a new prediction job on ML Engine.
Specifying where your data is and which model to use to make the prediction.
When a prediction is ready, it’s sent to the job (5) and ultimately returned back to you (6) with all the details of what happened.
ML Engine aims to minimize the management work you’ll need to do to train and interact with models.
18.3. Interacting with Cloud ML Engine
Overview of US Census data
This data is also available to the public, and you can use some of it to make some interesting predictions.
Subset, which includes basic personal information including education and employment details.
Dataset will contain things like an individual’s age, employment situation (for example, private employer, government employer, and so on), level of education, marital status, race, income category (for example, less than or more than $50,000 annual income), and more. Some simplified rows are shown.
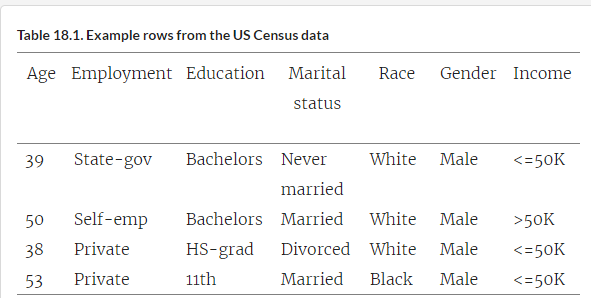
You can use all the other data in a row to train a model that can then make predictions about income category based on the other information.
Predict whether a person makes more than $50,000 in a year based on their age, employment status, marital status, and so on.
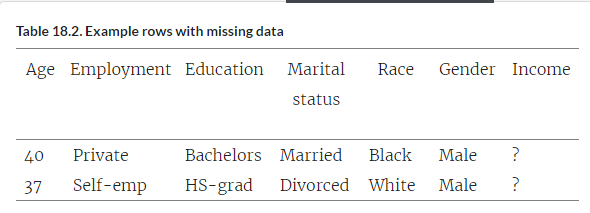
18.3.2. Creating a model
Model acts as a container of a prediction function that fulfills a specific contract
Model’s contract accepts rows of US Census data (with the income category field missing) as input and returns the predicted income category as output.
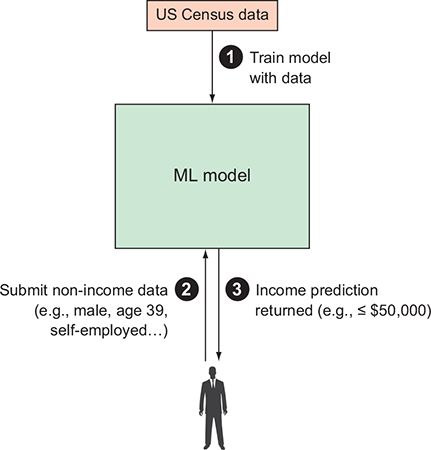
Using complete Census data to train your model to predict the income category field based on the rest of the row.
Finish training the model, you can then send it rows with the income category missing.
Send back predictions of the income category for that row.
Model is only a container, you can create it using the Cloud Console.
Choose ML Engine from the left-side navigation (it’s under Big Data).
Left hand side choose AI.

Summary
Machine learning is the overarching concept that you can train computers to perform a task using example data rather than explicitly programming them.
Neural networks are one method of training computers to perform tasks.
TensorFlow is an open source framework that makes it easy to express high-level machine-learning concepts (such as neural networks) in Python code.
Cloud Machine Learning Engine (ML Engine) is a hosted service for training and serving machine-learning models built with TensorFlow.
You can configure the underlying virtual hardware to be used in ML Engine, using either predefined tiers or more specific parameters (for example, machine types).
ML Engine charges based on hourly resource consumption (similar to other computing-focused services like Compute Engine) for both training and prediction jobs.
No comments:
Post a Comment