Chapter 15. Cloud Natural Language
An overview of natural language processing
How the Cloud Natural Language API works
The different types of analysis supported by Cloud Natural Language
How Cloud Natural Language pricing is calculated
An example to suggest hashtags
An overview of natural language processing
How the Cloud Natural Language API works
The different types of analysis supported by Cloud Natural Language
How Cloud Natural Language pricing is calculated
An example to suggest hashtags
Natural language processing is the act of taking text content as input and deriving some
structured meaning or understanding from it as output.
Take the sentence “I’m going to the mall” and derive {action: "going", target: "mall"}.
Joe drives his Broncos to work.
Sentence is ambiguous, and we can’t say with certainty whether it means that Joe forces
his bronco horses to his workplace, or he gets in one of the many Ford Bronco cars he
owns.
Natural language processing is complex and still an active area of research.
Cloud Natural Language API attempts to simplify this so that you can use machine
learning to process text content without keeping up with all the research papers.
Results are best guesses—treat the output as suggestions.
15.1. How does the Natural Language API work?
Natural Language API is a stateless API where you send it some input (in this case the
input is text), and the API returns some set of annotations about the text.
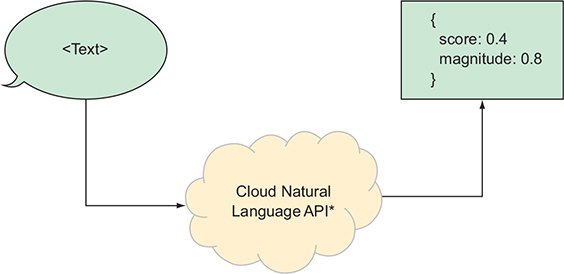
NL API can annotate three features of input text:
Syntax - parse a document into sentences, finding “tokens” along the way. These tokens
would have a part of speech, canonical form of the token.
Entities—look at each token individually and do a lookup in Google’s knowledge graph to
associate the two. pointer to a specific entity in the knowledge graph.
using the concept of salience (or “prominence”), you’ll be able to see whether the
sentence is focused on Barack Obama or whether he’s mentioned in passing.
Sentiment—ability to understand the emotional content involved in a chunk of text and recognize
that a given sentence expresses positive or negative emotion.
Values should be treated as somewhat “fuzzy”—even our human brains can’t necessarily
come up with perfectly correct answers.
15.2. Sentiment analysis
Recognizing the sentiment or emotion of what is said.
Humans, we can generally tell whether a given sentence is happy or sad.
The sentence “I like this car” is something most of us would consider to be positive.
“This car is ugly” would likely be considered to be “negative.”
A truly neutral sentence such as “This is a car.”.
Need to track both the sentiment itself as well as the magnitude of the overall sentiment.
Table 15.1. Comparing sentences with similar sentiment and different magnitudes
The overall sentiment as a vector, which conveys both a rating of the positivity
(or negativity), and a magnitude, which expresses how strongly that sentiment is
expressed.
Overall sentiment and magnitude, add the two vectors to get a final vector.

The score is significant - magnitude isn’t helpful.
Where the positive and negative cancel each other out, the magnitude can help
distinguish between a truly unemotional input and one where positivity and negativity
neutralize one another.
Send text to the Natural Language API, you’ll get back both a score and a magnitude,
which together represent these two aspects of the sentiment.
Score is close to zero, the magnitude value will represent how much emotion actually
went into it.
Magnitude will be a number greater than zero, with zero meaning that the statement
was truly neutral.
Enable the Natural Language API using the Cloud Console.
run npm install @google-cloud/language@0.8.0
const language = require('@google-cloud/language')({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
language.detectSentiment('This car is really pretty.').then((result) => {
console.log('Score:', result[0]);
});
run this code with the proper credentials
> Score: 0.5
Overall sentiment of that sentence was moderately positive.
Machine-learning APIs, the algorithms and underlying systems that generate the
outputs are constantly learning and improving.
const language = require('@google-cloud/language')({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
const content = 'This car is nice. It also gets terrible gas mileage!';
language.detectSentiment(content).then((result) => {
console.log('Score:', result[0]);
});
We predicted: a score of zero.
Compare two inputs while increasing the verbosity of the request
const language = require('@google-cloud/language')({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
const inputs = [
'This car is nice. It also gets terrible gas mileage!',
'This is a car.'
];
inputs.forEach((content) => {
language.detectSentiment(content, {verbose: true})
.then((result) => {
const data = result[0];
console.log([
'Results for "' + content + '":',
' Score: ' + data.score,
' Magntiude: ' + data.magnitude
].join('\n'));
});
});
See something like the following:
Results for "This is a car.":
Score: 0.20000000298023224
Magntiude: 0.20000000298023224
Results for "This car is nice. It also gets terrible gas mileage!":
Score: 0
Magntiude: 1.2999999523162842
The “neutral” sentence had quite a bit of emotion.
Thought to be a neutral statement (“This is a car”) is rated slightly positive overall,
Judging the sentiment of content is a bit of a fuzzy process
15.3. Entity recognition
Whether input text contains any special entities, such as people, places, organizations,
works of art, or anything else you’d consider a proper noun
Parsing the sentence for tokens and comparing those tokens against the entities that
Google has stored in its knowledge graph.
API is able to distinguish between terms that could be special, depending on their use
(such as “blackberry” the fruit versus “Blackberry” the phone).
Entity detection to determine which entities are present in your input.
const language = require('@google-cloud/language')({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
const content = 'Barack Obama prefers an iPhone over a Blackberry when ' +
'vacationing in Hawaii.';
language.detectEntities(content).then((result) => {
console.log(result[0]);
});
Something like the following:
> { people: [ 'Barack Obama' ],
goods: [ 'iPhone' ],
organizations: [ 'Blackberry' ],
places: [ 'Hawaii' ] }
Four distinct entities: Barack Obama, iPhone, Blackberry, and Hawaii.
Natural Language API can distinguish between differing levels of prominence.
Rank things according to how important they are in the sentence
const language = require('@google-cloud/language')({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
const content = 'Barack Obama prefers an iPhone over a Blackberry when ' +
'vacationing in Hawaii.';
const options = {verbose: true};
language.detectEntities(content, options).then((result) => {
console.log(result[0]);
});
Rather than seeing the names of the entities, you’ll see the entity raw content,
> { people:
[ { name: 'Barack Obama',
type: 'PERSON',
metadata: [Object],
salience: 0.5521853566169739,
mentions: [Object] } ],
goods:
[ { name: 'iPhone',
type: 'CONSUMER_GOOD',
metadata: [Object],
salience: 0.1787826418876648,
mentions: [Object] } ],
organizations:
[ { name: 'Blackberry',
type: 'ORGANIZATION',
metadata: [Object],
salience: 0.15308542549610138,
mentions: [Object] } ],
places:
[ { name: 'Hawaii',
type: 'LOCATION',
metadata: [Object],
salience: 0.11594659835100174,
mentions: [Object] } ] }
What effect does the phrasing have on salience?
const language = require('@google-cloud/language')({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
const inputs = [
'Barack Obama prefers an iPhone over a Blackberry when in Hawaii.',
'When in Hawaii an iPhone, not a Blackberry, is Barack Obama\'s
preferred device.',
];
const options = {verbose: true};
inputs.forEach((content) => {
language.detectEntities(content, options).then((result) => {
const entities = result[1].entities;
entities.sort((a, b) => {
return -(a.salience - b.salience);
});
console.log(
'For the sentence "' + content + '"',
'\n The most important entity is:', entities[0].name,
'(' + entities[0].salience + ')');
});
});
Different the values turn out to be given different phrasing of similar sentences.
> For the sentence "Barack Obama prefers an iPhone over a Blackberry when in
Hawaii."
The most important entity is: Barack Obama (0.5521853566169739)
For the sentence "When in Hawaii an iPhone, not a Blackberry, is Barack
Obama's preferred device."
The most important entity is: Hawaii (0.44054606556892395)
Natural Language API does support languages other than English—it currently
includes both Spanish (es) and Japanese (jp)
const language = require('@google-cloud/language')({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
language.detectEntities('Hugo Chavez era de Venezuela.', {
verbose: true,
language: 'es'
}).then((result) => {
console.log(result[0]);
});
> { people:
[ { name: 'Hugo Chavez',
type: 'PERSON',
metadata: [Object],
salience: 0.7915874123573303,
mentions: [Object] } ],
places:
[ { name: 'Venezuela',
type: 'LOCATION',
metadata: [Object],
salience: 0.20841257274150848,
mentions: [Object] } ] }
15.4. Syntax analysis
Diagram a sentence to point out the various parts of speech such as the phrases, verbs,
nouns, participles, adverbs
Dependency graphs, which allow you to see the core of the sentence and push modifiers
and other nonessential information to the side.
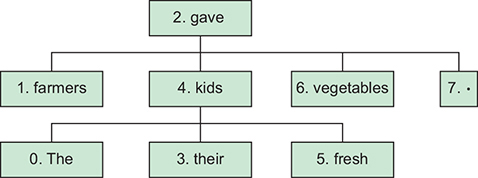
The farmers gave their kids fresh vegetables.

Dependency graph given the same sentence as input. The API offers the ability to build
a syntax tree to make it easier to build your own machine-learning algorithms on natural
language inputs.
Detected whether a sentence made sense.

API works by first parsing the input for sentences, tokenizing the sentence, recognizing
the part of speech of each word, and building a tree of how all the words fit together in
the sentence.
const language = require('@google-cloud/language')({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
const content = 'The farmers gave their kids fresh vegetables.';
language.detectSyntax(content).then((result) => {
const tokens = result[0];
tokens.forEach((token, index) => {
const parentIndex = token.dependencyEdge.headTokenIndex;
console.log(index, token.text, parentIndex);
});
});
Table of the dependency graph,
Table 15.2. Comparing sentences with similar sentiment and different magnitudes
Dependency tree
15.5. Understanding pricing
Cloud Natural Language API charges based on the usage.
The amount of text sent for analysis, with different rates for the different types of
analysis.
Send a long document for entity recognition, it’d be billed as the number of 1,000
character chunks needed to fit the entire document (ath.ceil(document.length / 1000.0)).
Table 15.4. Pricing example for Cloud Natural Language API
15.6. Case study: suggesting InstaSnap hash-tags
NL API is able to take some textual input and come up with both a sentiment analysis
as well as the entities in the input
Take a post’s caption as input text and send it to the Natural Language API. Next, the
Natural Language API would send back both sentiment and any detected entities.
After that, you’d have to coerce some of the results into a format that’s useful in this
scenario;
display a list of suggested tags to the user.

const language = require('@google-cloud/language')({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
const caption = 'SpaceX lands on Mars! Fantastic!';
constdocument = language.document(caption);
const options = {entities: true, sentiment: true, verbose: true};
document.annotate(options).then((data) => {
const result = data[0];
console.log('Sentiment was', result.sentiment);
console.log('Entities found were', result.entities);
});
> Sentiment was { score: 0.4000000059604645, magnitude: 0.800000011920929 }
Entities found were { organizations:
[ { name: 'SpaceX',
type: 'ORGANIZATION',
metadata: [Object],
salience: 0.7309288382530212,
mentions: [Object] } ],
places:
[ { name: 'Mars',
type: 'LOCATION',
metadata: [Object],
salience: 0.26907116174697876,
mentions: [Object] } ] }
apply some tags, starting with entities first. For most entities, you can toss a # character in front of the place and call it a day.
can come up with some happy and sad tags and use those when the sentiment passes
certain thresholds.
const getSuggestedTags = (sentiment, entities) => {
const suggestedTags = [];
const entitySuffixes = {
organizations: { positive: ['4Life', 'Forever'], negative: ['Sucks'] },
people: { positive: ['IsMyHero'], negative: ['Sad'] },
places: { positive: ['IsHome'], negative: ['IsHell'] },
};
const sentimentTags = {
positive: ['#Yay', '#CantWait', '#Excited'],
negative: ['#Sucks', '#Fail', '#Ugh'],
mixed: ['#Meh', '#Conflicted'],
};
// Start by grabbing any sentiment tags.
let emotion;
if (sentiment.score >0.1) {
emotion = 'positive';
} else if (sentiment.score < -0.1) {
emotion = 'negative';
} else if (sentiment.magnitude >0.1) {
emotion = 'mixed';
} else {
emotion = 'neutral';
}
// Add a random tag to the list of suggestions.
let choices = sentimentTags[emotion];
if (choices) {
suggestedTags.push(choices[Math.floor(Math.random() * choices.length)]);
}
// Now run through all the entities and attach some suffixes.
for (let category in entities) {
let suffixes;
try {
suffixes = entitySuffixes[category][emotion];
} catch (e) {
suffixes = [];
}
if (suffixes.length) {
entities[category].forEach((entity) => {
let suffix = suffixes[Math.floor(Math.random() * suffixes.length)];
suggestedTags.push('#' + entity.name + suffix);
});
}
}
// Return all of the suggested tags.
return suggestedTags;
};
come up with some suggested tags should look simple
const language = require('@google-cloud/language')({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
const caption = 'SpaceX lands on Mars! Fantastic!';
constdocument = language.document(caption);
const options = {entities: true, sentiment:true, verbose: true};
document.annotate(options).then((data) => {
const sentiment = data[0].sentiment;
const entities = data[0].entities;
const suggestedTags =
getSuggestedTags(sentiment, entities);
console.log('The suggested tags are', suggestedTags);
console.log('The suggested caption is',
'"' + caption + ' ' + suggestedTags.join(' ') + '"');
});
> The suggested tags are [ '#Yay', '#SpaceX4Life', '#MarsIsHome' ]
The suggested caption is "SpaceX lands on Mars! Fantastic! #Yay #SpaceX4Life
#MarsIsHome"
Summary
The Natural Language API is a powerful textual analysis service.
If you need to discover details about text in a scalable way, the Natural Language API is likely a good fit for you.
The API can analyze text for entities (people, places, organizations), syntax (tokenizing and diagramming sentences), and sentiment (understanding the emotional content of text).
As with all machine learning today, the results from this API should be treated as suggestions rather than absolute fact (after all, it can be tough for people to decide whether a given sentence is happy or sad).
The Natural Language API is a powerful textual analysis service.
If you need to discover details about text in a scalable way, the Natural Language API is likely a good fit for you.
The API can analyze text for entities (people, places, organizations), syntax (tokenizing and diagramming sentences), and sentiment (understanding the emotional content of text).
As with all machine learning today, the results from this API should be treated as suggestions rather than absolute fact (after all, it can be tough for people to decide whether a given sentence is happy or sad).
No comments:
Post a Comment