Chapter 14. Cloud Vision
An overview of image recognition
The different types of recognition supported by Cloud Vision
How Cloud Vision pricing is calculated
An example evaluating whether profile images are acceptable
Difficult to get a computer to recognize an image.
Things that are hard to define are typically tricky to express as code.
Cloud Vision, look at image recognition as being able to slap a bunch of annotations
on a given image.

How a human might label an image, adding several annotations to different areas of the image.
Annotations aren’t limited to things like “dog” but can be other attributes, such as colors like “green.”
Conceptual understanding.
Argument on the internet over the color of a dress.
Millions of people couldn’t decide on the color of a dress.
Image recognition is super complicated.
Image recognition is not an exact science.
Encourage you to build some fudge factor into your code.
Taking the results of a particular annotation as a suggestion rather than absolute fact.
14.1. Annotating images
General flow for annotating images is a simple request-response pattern.
Send an image along with the desired annotations you’re interested in to the Cloud Vision API.
API sends back a response containing all of those annotations.

Send your image and get back some details about it.
Because there’s no state to maintain, specify which annotation types you’re interested in, and the result will be limited to those.
14.1.1. Label annotations
Labels are a quick textual description of a concept that Cloud Vision recognized in the image.
Image recognition is not an exercise leading to absolute facts.
Asks the Cloud Vision API to put label annotations on your image.
In general it’s best to treat the results as suggestions to be validated later by a human.
What is a service account?
A service account is an identity that an instance or an application can use to run API requests on your behalf.
Create a service account and grant the service account access to the Cloud.
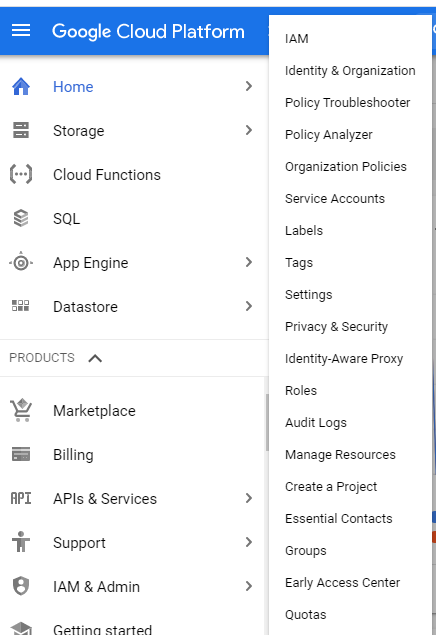
Create and manage your own service accounts using Cloud Identity and Access Management.
To get a service account, in the Cloud Console choose IAM & Admin from the left-side navigation, and then choose Service Accounts.

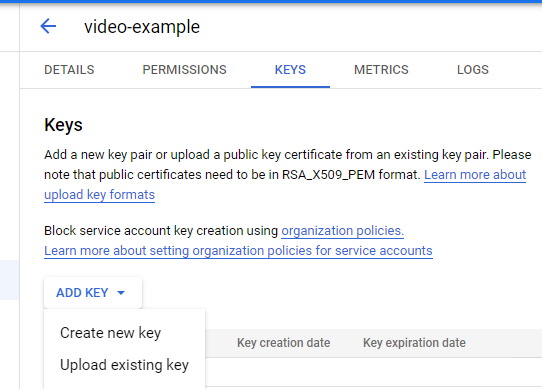
Click Create Service Account, and fill in some details as shown in




Install the client library. To do this, run npm install @google-cloud/vision@0.11.5
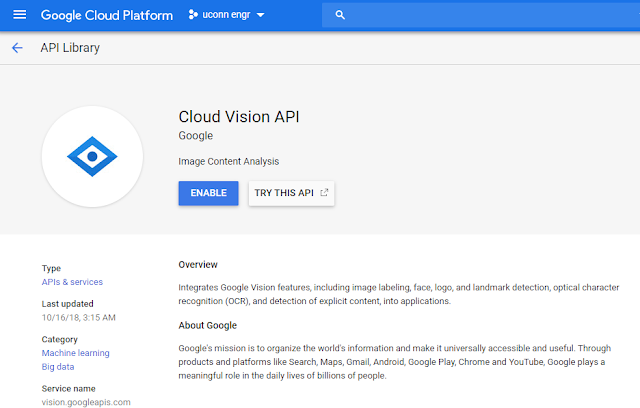
Enable the Cloud Vision API using the Cloud Console.
Search bar at the top of the Cloud Console, enter Cloud Vision API.
const vision = require('@google-cloud/vision')({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
vision.detectLabels('dog.jpg').then((data) => {
console.log('labels: ', data[0].join(', '));
});
output
> labels: dog, mammal, vertebrate, setter, dog like mammal
labels go from specific to vague,
Ask Cloud Vision, “Show me only labels that you’re 75% confident in”?
Turn on verbose mode
const vision = require('@google-cloud/vision')({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
vision.detectLabels('dog.jpg', {verbose: true})
.then((data) => {
const labels = data[0];
labels.forEach((label) => {
console.log(label);
});
});
Provides more details
> { desc: 'dog', mid: '/m/0bt9lr', score: 96.969336 }
{ desc: 'mammal', mid: '/m/04rky', score: 92.070323 }
{ desc: 'vertebrate', mid: '/m/09686', score: 89.664793 }
{ desc: 'setter', mid: '/m/039ndd', score: 69.060057 }
{ desc: 'dog like mammal', mid: '/m/01z5f', score: 68.510407 }
Label values are the same, but they also include two extra fields: mid and score.
Mid value is an opaque ID for the label that you should store i
Score is a confidence level for each label
Indication of how confident the Vision API is in each label
const vision = require('@google-cloud/vision')({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
vision.detectLabels('dog.jpg', {verbose: true}).then((data) => {
const labels = data[0]
.filter((label) => { return label.score >75; })
.map((label) => { return label.desc; });
console.log('Accurate labels:', labels.join(', '));
});
See only the labels with confidence greater than 75%
> Accurate labels: dog, mammal, vertebrate
14.1.2. Faces
Details about faces in the image
Details about the emotions of the face in the picture
Happiness, anger, and surprise
Scores, confidences, and likelihoods.
Simple test to detect whether an image has a face.
const vision = require('@google-cloud/vision')({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
vision.detectFaces('dog.jpg').then((data) => {
const faces = data[0];
if (faces.length) {
console.log("Yes! There's a face!");
} else {
console.log("Nope! There's no face in that image.");
}
});
the dog’s face doesn’t count:
> Nope! There's no face in that image.

Face and all the various annotations that come back on the image.
const vision = require('@google-cloud/vision')({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
vision.detectFaces('kid.jpg').then((data) => {
const faces = data[0];
faces.forEach((face) => {
console.log('How sure are we that there is a face?', face.confidence + '%');
console.log('Does the face look happy?', face.joy ? 'Yes' : 'No');
console.log('Does the face look angry?', face.anger ? 'Yes' : 'No');
});
});
You’re very sure that there is a face, and that the face is happy
> How sure are we that there is a face? 99.97406%
Does the face look happy? Yes
Does the face look angry? No
@google-cloud/vision client library for Node.js is making some assumptions for you, saying “If the likelihood is LIKELY or VERY_LIKELY, then use true.”
const vision = require('@google-cloud/vision')({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
vision.detectFaces('kid.jpg').then((data) => {
const rawFaces = data[1]['responses'][0].faceAnnotations;
const faces = data[0];
faces.forEach((face, i) => {
const rawFace = rawFaces[i];
console.log('How sure are we that there is a face?', face.confidence + '%');
console.log('Are we certain the face looks happy?',
rawFace.joyLikelihood == 'VERY_LIKELY' ? 'Yes' : 'Not really');
console.log('Are we certain the face looks angry?',
rawFace.angerLikelihood == 'VERY_LIKELY' ? 'Yes' : 'Not really');
});
});
> How sure are we that there is a face? 99.97406005859375%
Are we certain the face looks happy? Yes
Are we certain the face looks angry? Not really
14.1.3. Text recognition
Text recognition (sometimes called OCR for optical character recognition).
Scan documents to create an image of the document, but they wanted to be able to edit.
Recognize the words and convert the document from an image to text that you could treat like any other electronic document.

const vision = require('@google-cloud/vision')({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
vision.detectText('wine.jpg').then((data) => {
const textAnnotations = data[0];
console.log('The label says:', textAnnotations[0].replace(/\n/g, ' '));
});
> The label says: BROOKLYN COWBOY WINERY
Do its best to find text in an image and turn it into text.
Some subjective aspect to putting text together to be useful.

Easy for us humans to understand what’s written on this card.
Computer, this card presents some difficult aspects.
Text is in a long-hand font with lots of flourishes and overlaps. Second, the “so” is in a bit of a weird position.
const vision = require('@google-cloud/vision')({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
vision.detectText('card.png', {verbose: true})
.then((data) => {
const textAnnotations = data[0];
textAnnotations.forEach((item) => {
console.log(item);
});
});
Vision API can understand only the “Evelyn & Sebastian” text at the bottom and doesn’t find anything else in the image.
> { desc: 'EVELYN & SEBASTIAN\n',
bounds:
[ { x: 323, y: 357 },
{ x: 590, y: 357 },
{ x: 590, y: 379 },
{ x: 323, y: 379 } ] }
{ desc: 'EVELYN',
bounds:
[ { x: 323, y: 357 },
{ x: 418, y: 357 },
{ x: 418, y: 379 },
{ x: 323, y: 379 } ] }
{ desc: '&;',
bounds:
[ { x: 427, y: 357 },
{ x: 440, y: 357 },
{ x: 440, y: 379 },
{ x: 427, y: 379 } ] }
{ desc: 'SEBASTIAN',
bounds:
[ { x: 453, y: 357 },
{ x: 590, y: 357 },
{ x: 590, y: 379 },
{ x: 453, y: 379 } ] }
Understanding images is complicated and computers aren’t quite to the point where they perform better than humans.
14.1.4. Logo recognition
Logos often tend to be combinations of text and art.
To take down images that contain copyrighted or trademarked material.
Logo detection in the Cloud Vision API comes in.
Find and identify popular logos independent of whether they contain the name of the company in the image.

const vision = require('@google-cloud/vision')({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
vision.detectLogos('logo.png').then((data) => {
const logos = data[0];
console.log('Found the following logos:', logos.join(', '));
});
> Found the following logos: FedEx

Same code again on this logo.
> Found the following logos: Tostitos
Logo with no text and an image.

> Found the following logos: Starbucks

> Found the following logos: Pizza Hut, KFC
14.1.5. Safe-for-work detection
Each workplace would need to make its own decisions about whether something is appropriate.
Supreme Court of the United States wasn’t quite able to quantify pornography, famously falling back on a definition of “I know it when I see it.”
Unreasonable to expect a computer to be able to define it.
Fuzzy number is better than no number at all.
Be comfortable relying on this fuzziness because it’s the same vision algorithm that filters out unsafe images when you do a Google search for images.
Different safe attributes that the Cloud Vision API can detect.
Pornography, known by the API as “adult” content.
Likelihood is whether the image likely contains any type of adult material, with the most common type being nudity or pornography.
Whether the image represents medical content (such as a photo of surgery or a rash).
Medical images and adult images can overlap, many images are adult content and not medical.
An image depicts any form of violence.
Violence tends to be something subjective that might differ depending on who is looking at it.
Safe search is called spoof detection.
Practice detects whether an image appears to have been altered somehow
particularly if the alternations lead to the image looking offensive
putting devil horns onto photos of celebrities, or other similar alterations.
Different categories of safety detection.
Investigate whether you should consider it safe for work.
const vision = require('@google-cloud/vision')({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
vision.detectSafeSearch('dog.jpg').then((data) => {
const safeAttributes = data[0];
console.log(safeAttributes);
});
> { adult: false, spoof: false, medical: false, violence: false }
These true and false values are likelihoods where LIKELY and VERY_LIKELY become true and anything else becomes false.
const vision = require('@google-cloud/vision')({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
vision.detectSafeSearch('dog.jpg', {verbose: true}).then((data) => {
const safeAttributes = data[0];
console.log(safeAttributes);
});
> { adult: 'VERY_UNLIKELY',
spoof: 'VERY_UNLIKELY',
medical: 'VERY_UNLIKELY',
violence: 'VERY_UNLIKELY' }
14.1.6. Combining multiple detection types
Cloud Vision API was designed to allow multiple types of detection in a single API call.
Call detectText, for example, is specifically asking for only a single aspect to be analyzed.
Use the generic detect method to pick up multiple things at once.

const vision = require('@google-cloud/vision')({
projectId: 'your-project-id',
keyFilename: 'key.json'
});
vision.detect('protest.png', ['logos', 'safeSearch', 'labels']).then((data) => {
const results = data[0];
console.log('Does this image have logos?', results.logos.join(', '));
console.log('Are there any labels for the image?', results.labels.join(', '));
console.log('Does this image show violence?',
results.safeSearch.violence ? 'Yes' : 'No');
});
Some labels and logos occur in the image.
> Does this image have logos? McDonald's
Are there any labels for the image? crowd
Does this image show violence? No
Pricing for the Cloud Vision API
14.2. Understanding pricing
Cloud Vision follows a pay-as-you-go pricing model where you’re charged a set amount for each API request you make.
You’re charged a set amount for each API request you make.
It’s not each API request that costs money but each type of detection.
You can use a specific Cloud Vision API tier with the first 1,000 requests per month absolutely free. The examples we went through should cost you absolutely nothing. After those free requests are used up, the price is $1.50 for every chunk of 1,000 requests (about $.0015 per request).
14.3. Case study: enforcing valid profile photos
InstaSnap is a cool application that allows you to upload images and share them with your friends.
Where you might store the images.
Make sure that a profile photo has a person in it?
Should be familiar with the detection type that you’ll need here: faces.

{kind=link}
User would start by uploading a potential profile photo to your InstaSnap application (1)
Saved to Cloud Storage (2)
Send it to the Cloud Vision API (3)
Use the response content to flag whether there were faces or not (4)
Pass that flag back to the user (5)
const imageHasFace = (imageUrl) => {
return vision.detectFaces(imageUrl).then( (data) => {
const faces = data[0];
return (faces.length == 0);
});
}
Plug it into your request handler that’s called when users upload new profile photos.
const handleIncomingProfilePhoto = (req, res) => {
const apiResponse = {};
const url = req.user.username + '-profile-' + req.files.photo.name;
return uploadToCloudStorage(url, req.files.photo)
.then( () => {
apiResponse.url = url;
return imageHasFace(url);
})
.then( (hasFace) => {
apiResponse.hasFace = hasFace;
})
.then( () =>1 {
res.send(apiResponse);
});
}
Summary
Image recognition is the ability to take a chunk of visual content (like a photo) and annotate it with information (such as textual labels).
Cloud Vision is a hosted image-recognition service that can add lots of different annotations to photos, including recognizing faces and logos, detecting whether content is safe, finding dominant colors, and labeling things that appear in the photo.
Because Cloud Vision uses machine learning, it is always improving. This means that over time the same image may produce different (likely more accurate) annotations.
No comments:
Post a Comment